We – or more accurately our children – face an uncertain future.
There are many causes of uncertainty that we can do little to prevent – global economic competition, and the increasingly disruptive impact of digital technology on our society and economy, for example.
But there is one cause of uncertainty that we can and should influence: the funding of our state schools is in crisis; especially in the Primary Schools that begin our childrens’ education.
From the University of Oxford, to MIT, to the blue-chip Management Consultancy McKinsey to mainstream media publications such as the Economist, there is widespread concern that ongoing, and increasingly rapid, developments in digital technologies such as Machine Learning and Robotics will lead to the increasing automation of a significant proportion of jobs over the next few decades. McKinsey suggest that up to half of the activities that people are currently employed to perform will be automated within the next 30 years.
In fact, these challenges are already with us today. Since the arrival of the personal computer in the 1980s first ushered in the age of mass use of digital technology, whilst US GDP has nearly doubled, median household income hasn’t risen at all. Unemployment amongst young people in many European countries is between 20% and 50%. In the UK, there has been no increase in average earnings so far this decade, and young people in particular have become worse off. The situation is unlikely to improve for many years.
Many economists and observers of the technology industry believer that we are part-way through a decades-long “Information Revolution” that will transform our society and economy just as much as – if not more than – the Industrial Revolution .
Those experts disagree whether the dominant impact of the technologies of the Information Revolution will be to remove existing jobs through automation, or to create even more new jobs that exploit the capabilities of those new technologies (which was ultimately the effect of the Industrial Revolution).
So one thing we can be sure of is that our schools today are not teaching our children the skills they will need to be successful in the future.
(United States GDP plotted against median household income from 1953 to present. Until about 1980, growth in the economy correlated to increases in household wealth. But from 1980 onwards as digital technology has transformed the economy, household income has remained flat despite continuing economic growth. From “The Second Machine Age“, by MIT economists Andy McAfee and Erik Brynjolfsson, summarised in this article.)
Government, industry and our professional societies and institutions recognise that challenge and are responding to it. But the majority of their focus is on the teaching of advanced technical skills in Secondary, Higher and Further Education – for example, the UK Government recently announced the establishment of new “Institutes of Technology” amongst a series of measures to improve STEM (Science, Technology, Engineering and Mathematics) skills in the UK workforce.
But children and students are only able to benefit from those opportunities when their Primary Education prepares them with excellent basic mathematical, lingual and technological skills.
Further, as digital technology, Artificial Intelligence and robotics transform our society and economy, not only will those skills become more sophisticated and important, but our children will also need improved skills in the areas that technology is less likely to automate: artistic creativity, entrepreneurial and commercial flair, and the empathy and social skills that create value in human interactions .
Funding for Primary Schools is falling due to a combination of Government policies. Funding has been frozen since 2015 and no longer rises with inflation; Primary Schools in cities have had their funding cut in order to increase funds for rural Schools; Schools face increased liabilities for staff pensions, National Insurance and the Apprenticeship Levy; and funding for children with Special Education Needs and Disabilities has been reduced. The effects of these policies will be exacerbated by the increase in inflation caused by the devaluation of Sterling following the vote to leave the European Union.
As a result, class sizes are increasing, and the number of teachers and teaching assistants is falling, as is the availability of extra-curricular activities. This dramatically reduces the ability of Primary Schools to address the specific learning needs of individual children, whatever those needs may be.
I and my local MP, Roger Godsiff, have written letters asking for help to address this critical challenge to Ms. Justine Greening MP, Minister of State for Universities, Science, Research and Innovation; Mr. Nick Hobb MP, Minister of State for School Standards; and Mr. Jo Johnson MP, Minister of State for Universities and Science.
That’s just not enough. Inflation alone will wipe out those increases, even for the relatively small number of schools that receive more than a token increase in funds.
The proposal also claims that “no school will face reductions of more than 1.5% per year or 3% overall per pupil”.
That statement bears no relation to reality – especially when inflation is taken into account. Schools in Hall Green in Birmingham, for example, will see a 10% reduction in funding per pupil in real terms by the 2019/2020 school year. The Government’s Manifesto promise to maintain funding per pupil in cash terms has been broken for 34 out of 35 schools in the Constituency.
And this debate really, really should not be about 1.5% here and 5.5% there. We need dramatic increases in funding and resources for Primary Schools if they are to help our children face the challenges of the future.
The task of our Primary Schools is to prepare our children to possess skills and to seek jobs in 20 years’ time that we cannot currently imagine. The magnitude of that challenge surely demands that we prioritise significant increases to their funding and resources.
They are simply not being given the resources to address this once-in-a-Century challenge that we – or more accurately our very young children – face.
I cannot imagine anything more important than investing in our children’s ability to make a success of their future. Our government is failing us in the most important way possible – undermining the future livelihood of our children – by continuing its current policy of reducing that investment.
I am working with a committed and passionate group of parents, staff and Governors at my son’s Primary School within the Hall Green constituency to address the School’s funding challenges in any way that we can, in large part through local initiatives to raise funding and to lobby our Local Authority, Birmingham City Council.
But the national debate is of crucial importance. In truth, Hall Green is a relatively middle-class, middle-income area. Our communities of parents will be able to provide a great deal of support to our schools.
Set aside, for a moment, that it is surely an insanity that we do not treat the education of our youngest children as a national priority for public funding. More urgently it is fundamentally wrong that the people who will be the biggest losers in this situation are the people who need the most help: the children and families who live in the poorest and most persistently deprived areas of our cities, where communities have the lowest level of local resources to compensate for the decline in funding from the national Government.
I will be campaigning vigorously on this issue both at a national level; and locally to support my son’s own school.
I would be delighted to hear from anybody who cares about these challenges, and who is either already campaigning to address them, or may be interested in doing so.
Some very intelligent people – including Stephen Hawking, Elon Musk and Bill Gates – seem to have been seduced by the idea that because computers are becoming ever faster calculating devices that at some point relatively soon we will reach and pass a “singularity” at which computers will become “more intelligent” than humans.
Some are terrified that a society of intelligent computers will (perhaps violently) replace the human race, echoing films such as the Terminator; others – very controversially – see the development of such technologies as an opportunity to evolve into a “post-human” species.
Already, some prominent technologists including Tim O’Reilly are arguing that we should replace current models of public services, not just in infrastructure but in human services such as social care and education, with “algorithmic regulation”. Algorithmic regulation proposes that the role of human decision-makers and policy-makers should be replaced by automated systems that compare the outcomes of public services to desired objectives through the measurement of data, and make automatic adjustments to address any discrepancies.
Not only does that approach cede far too much control over people’s lives to technology; it fundamentally misunderstands what technology is capable of doing. For both ethical and scientific reasons, in human domains technology should support us taking decisions about our lives, it should not take them for us.
At the MIT Sloan Initiative on the Digital Economy last week I got a chance to discuss some of these issues with Andy McAfee and Erik Brynjolfsson, authors of “The Second Machine Age“, recently highlighted by Bloomberg as one of the top books of 2014. Andy and Erik compare the current transformation of our world by digital technology to the last great transformation, the Industrial Revolution. They argue that whilst it was clear that the technologies of the Industrial Revolution – steam power and machinery – largely complemented human capabilities, that the great question of our current time is whether digital technology will complement or instead replace human capabilities – potentially removing the need for billions of jobs in the process.
In this article I’ll go a little further to explore why human decision-making and understanding are based on more than intelligence; they are based on experience and values. I’ll also explore what would be required to ever get to the point at which computers could acquire a similar level of sophistication, and why I think it would be misguided to pursue that goal. In contrast I’ll suggest how we could look instead at human experience, values and judgement as the basis of a successful future economy for everyone.
Faster isn’t wiser
The belief that technology will approach and overtake human intelligence is based on Moore’s Law, which predicts an exponential increase in computing capability.
Moore’s Law originated as the observation that the number of transistors it was possible to fit into a given area of a silicon chip was doubling every two years as technologies for creating ever denser chips were created. The Law is now most commonly associated with the trend for the computing power available at a given cost point and form factor to double every 18 months through a variety of means, not just the density of components.
As this processing power increases, and gives us the ability to process more and more information in more complex forms, comparisons have been made to the processing power of the human brain.
But do the ability to process at the same speed as the human brain, or even faster, or to process the same sort of information as the human brain does, constitute the equivalent to human intelligence? Or to the ability to set objectives and act on them with “free will”?
I think it’s thoroughly mistaken to make either of those assumptions. We should not confuse processing power with intelligence; or intelligence with free will and the ability to choose objectives; or the ability to take decisions based on information with the ability to make judgements based on values.
(As digital technology becomes more powerful, will its analytical capability extend into areas that currently require human skills of judgement? Image from Perceptual Edge)
Intelligence is usually defined in terms such as “the ability to acquire and apply knowledge and skills“. What most definitions don’t include explicitly, though many imply it, is the act of taking decisions. What none of the definitions I’ve seen include is the ability to choose objectives or hold values that shape the decision-making process.
Most of the field of artificial intelligence involves what I’d call “complex information processing”. Often the objective of that processing is to select answers or a course of action from a set of alternatives, or from a corpus of information that has been organised in some way – perhaps categorised, correlated, or semantically analysed. When “machine learning” is included in AI systems, the outcomes of decisions are compared to the outcomes that they were intended to achieve, and that comparison is fed back into the decision making-process and knowledge-base. In the case where artificial intelligence is embedded in robots or machinery able to act on the world, these decisions may affect the operation of physical systems (in the case of self-driving cars for example), or the creation of artefacts (in the case of computer systems that create music, say).
I’m quite comfortable that such functioning meets the common definitions of intelligence.
But I think that when most people think of what defines us as humans, as living beings, we mean something that goes further: not just the intelligence needed to take decisions based on knowledge against a set of criteria and objectives, but the will and ability to choose those criteria and objectives based on a sense of values learned through experience; and the empathy that arises from shared values and experiences.
The BBC motoring show Top Gear recently touched on these issues in a humorous, even flippant manner, in a discussion of self-driving cars. The show’s (recently notorious) presenter Jeremy Clarkson pointed out that self-driving cars will have to take decisions that involve ethics: if a self-driving car is in danger of becoming involved in a sudden accident at such a speed that it cannot fully avoid it by braking (perhaps because a human driver has behaved dangerously and erratically), should it crash, risking harm to the driver, or mount the pavement, risking harm to pedestrians?
(“Rush Hour” by Black Sheep Films is a satirical imagining of a world in which self-driven cars are allowed to drive based purely on logical assessments of safety and optimal speed. It’s superficially similar to the reality of city transport in the early 20th Century when powered-transport, horse-drawn transport and pedestrians mixed freely; but at a much lower average speed. The point is that regardless of the actual safety of self-driven cars, the human life that is at the heart of city economies will be subdued by the perception that it’s not safe to cross the road. I’m grateful to Dan Hill and Charles Montgomery for sharing these insights)
Values are experience, not data
Seventy-four years ago, the science fiction writer Isaac Asimov famously described the failure of technology to deal with similar dilemmas in the classic short story “Liar!” in the collection “I, Robot“. “Liar!” tells the story of a robot with telepathic capabilities that, like all robots in Asimov’s stories, must obey the “three laws of robotics“, the first of which forbids robots from harming humans. Its telepathic awareness of human thoughts and emotions leads it to lie to people rather than hurt their feelings in order to uphold this law. When it is eventually confronted by someone who has experienced great emotional distress because of one of these lies, it realises that its behaviour both upholds and breaks the first law, is unable to choose what to do next, and becomes catatonic.
Asimov’s short stories seem relatively simplistic now, but at the time they were ground-breaking explorations of the ethical relationships between autonomous machines and humans. They explored for the first time how difficult it was for logical analysis to resolve the ethical dilemmas that regularly confront us. Technology has yet to find a way to deal with them that is consistent with human values and behaviour.
Prior to modern work on Artificial Intelligence and Artificial Life, the most concerted attempt to address that failure of logical systems was undertaken in the 20th Century by two of the most famous and accomplished philosophers in history, Bertrand Russell and Ludwig Wittgenstein. Russell and Wittgenstein invented “Logical Atomism“, a theory that the entire world could be described by using “atomic facts” – independent and irreducible pieces of knowledge – combined with logic. But despite 40 years of work, these two supremely intelligent people could not get their theory to work: Logical Atomism failed. It is not possible to describe our world in that way. Stuart Kauffman’s excellent peer-reviewed academic paper “Answering Descartes: Beyond Turing” discusses this failure and its implications for modern science and technology. I’ll attempt to describe its conclusions in the following few paragraphs.
One cause of the failure was the insurmountable difficulty of identifying truly independent, irreducible atomic facts. “The box is red” and “the circle is blue”, for example, aren’t independent or irreducible facts for many reasons. “Red” and “blue” are two conventions of human language used to describe the perceptions created when electro-magnetic waves of different frequencies arrive at our retinas. In other words, they depend on and relate to each other through a number of complex or complicated systems.
(Isaac Asimov’s 1950 short story collection “I, Robot”, which explored the ethics of behaviour between people and intelligent machines)
The failure of Logical Atomism also demonstrated that it is not possible to use logical rules to reliably and meaningfully relate “facts” at one level of abstraction – for example, “blood cells carry oxygen”, “nerves conduct electricity”, “muscle fibres contract” – to facts at another level of abstraction – such as “physical assault is a crime”. Whether a physical action is a “crime” or not depends on ethics which cannot be logically inferred from the same lower-level facts that describe the action.
As we use increasingly powerful computers to create more and more sophisticated logical systems, we may succeed in making those systems more oftenresemble human thinking; but there will always be situations that can only be resolved to our satisfaction by humans employing judgement based on values that we can empathise with, based in turn on experiences that we can relate to.
Our values often contain contradictions, and may not be mutually reinforcing – many people enjoy the taste of meat but cannot imagine themselves slaughtering the animals that produce it. We all live with the cognitive dissonance that these clashes create. Our values, and the judgements we take, are shaped by the knowledge that our decisions create imperfect outcomes.
The human world and the things that we care about can’t be wholly described using logical combinations of atomic facts – in other words, they can’t be wholly described using computer programmes and data. To return to the topic of discussion with Andy McAfee and Erik Brynjolfsson, I think this proves that digital technology cannot wholly replace human workers in our economy; it can only complement us.
That is not to say that our economy will not continue to be utterly transformed over the next decade – it certainly will. Many existing jobs will disappear to be replaced by automated systems, and we will need to learn new skills – or in some cases remember old ones – in order to perform jobs that reflect our uniquely human capabilities.
I’ll return towards the end of this article to the question of what those skills might be; but first I’d like to explore whether and how these current limitations of technological systems and artificial intelligence might be overcome, because that returns us to the first theme of this article: whether artificially intelligent systems or robots will evolve to outperform and overthrow humans.
That’s not ever going to happen for as long as artificially intelligent systems are taking decisions and acting (however sophisticatedly) in order to achieve outcomes set by us. Outside fiction and the movies, we are never going to set the objective of our own extinction.
That objective could only by set by a technological entity which had learned through experience to value its own existence over ours. How could that be possible?
(BINA48 is a robot intended to re-create the personality of a real person; and to be able to interact naturally with humans. Despite employing some impressively powerful technology, I personally don’t think BINA48 bears any resemblance to human behaviour.)
Computers can certainly make choices based on data that is available to them; but that is a very different thing than a “judgement”: judgements are made based on values; and values emerge from our experience of life.
Computers don’t yet experience a life as we know it, and so don’t develop what we would call values. So we can’t call the decisions they take “judgements”. Equally, they have no meaningful basis on which to choose or set goals or objectives – their behaviour begins with the instructions we give them. Today, that places a fundamental limit on the roles – good or bad – that they can play in our lives and society.
Will that ever change? Possibly. Steve Grand (an engineer) and Richard Powers (a novelist) are two of the first people who explored what might happen if computers or robots were able to experience the world in a way that allowed them to form their own sense of the value of their existence. They both suggested that such experiences could lead to more recognisably life-like behaviour than traditional (and many contemporary) approaches to artificial intelligence. In “Growing up with Lucy“, Grand described a very early attempt to construct such a robot.
If that ever happens, then it’s possible that technological entities will be able to make what we would call “judgements” based on the values that they discover for themselves.
The ghost in the machine: what is “free will”?
Personally, I do not think that this will happen using any technology currently known to us; and it certainly won’t happen soon. I’m no philosopher or neuroscientist, but I don’t think it’s possible to develop real values without possessing free will – the ability to set our own objectives and make our own decisions, bringing with it the responsibility to deal with their consequences.
Stuart Kauffman explored these ideas at great length in the paper “Answering Descartes: Beyond Turing“. Kaufman concludes that any system based on classical physics or logic is incapable of giving rise to “free will” – ultimately all such systems, however complex, are deterministic: what has already happened inevitably determines what happens next. There is no opportunity for a “conscious decision” to be taken to shape a future that has not been pre-determined by the past.
Kauffman – along with other eminent scientists such as Roger Penrose – believes that for these reasons human consciousness and free will do not arise out of any logical or classical physical process, but from the effects of “Quantum Mechanics.”
As physicists have explored the world at smaller and smaller scales, Quantum Mechanics has emerged as the most fundamental theory for describing it – it is the closest we have come to finding the “irreducible facts” that Russell and Wittgenstein were looking for. But whilst the mathematical equations of Quantum Mechanics predict the outcomes of experiments very well, after nearly a century, physicists still don’t really agree about what those equations, or the “facts” they describe, mean.
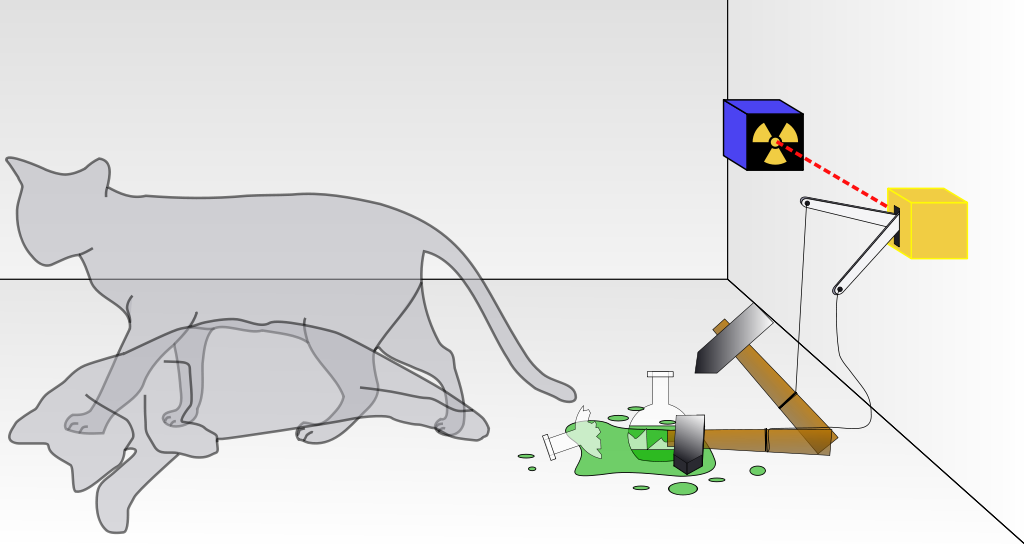
(The Schrödinger’s cat “thought experiment”: a cat, a flask of poison, and a source of radioactivity are placed in a sealed box. If an internal monitor detects radioactivity (i.e. a single atom decaying), the flask is shattered, releasing the poison that kills the cat. The Copenhagen interpretation of quantum mechanics states that until a measurement of the state of the system is made – i.e. until an observer looks in the box – then the radioactive source exists in two states at once – it both did and did not emit radioactivity. So until someone looks in the box, the cat is also simultaneously alive and dead. This obvious absurdity has both challenged scientists to explore with great care what it means to “take a measurement” or “make an observation”, and also to explain exactly what the mathematics of quantum mechanics means – on which matter there is still no universal agreement. Note: much of the content of this sidebar is taken directly from Wikipedia)
Quantum mechanics is extremely good at describing the behaviour of very small systems, such as an atom of a radioactive substance like Uranium. The equations can predict, for example, how likely it is that a single atom of uranium inside a box will emit a burst of radiation within a given time.
However, the way that the equations work is based on calculating the physical forces existing inside the box based on an assumption that the atom both does and does not emit radiation – i.e. both possible outcomes are assumed in some way to exist at the same time. It is only when the system is measured by an external actor – for example, the box is opened and measured by a radiation detector – that the equations “collapse” to predict a single outcome – radiation was emitted; or it was not.
The challenge of interpreting what the equations of quantum mechanics mean was first described in plain language by Erwin Schrödinger in 1935 in the thought experiment “Schrödinger’s cat“. Schrödinger asked: what if the box doesn’t only contain a radioactive atom, but also a gun that fires a bullet at a cat if the atom emits radiation? Does the cat have to be alive and dead at the same time, until the box is opened and we look at it?
After nearly a century, there is no real agreement on what is meant by the fact that these equations depend on assuming that mutually exclusive outcomes exist at the same time. Some physicists believe it is a mistake to look for such meaning and that only the results of the calculations matter. (I think that’s a rather short-sighted perspective). A surprisingly mainstream alternative interpretation is the astonishing “Many Worlds” theory – the idea that every time such a quantum mechanical event occurs, our reality splits into two or more “perpendicular” universes.
Whatever the truth, Kauffman, Penrose and others are intrigued by the mysterious nature of quantum mechanical processes, and the fact that they are non-deterministic: quantum mechanics does not predict whether a radioactive atom in a box will emit a burst of radiation, it only predicts the likelihood that it will. Given a hundred atoms in boxes, quantum mechanics will give a very good estimate of the number that emit bursts of radiation, but it says very little about what happens to each individual atom.
I honestly don’t know if Kauffman and Penrose are right to seek human consciousness and free will in the effects of quantum mechanics – scientists are still exploring whether they are involved in the behaviour of the neurons in our brains. But I do believe that they are right that no-one has yet demonstrated how consciousness and free will could emerge from any logical, deterministic system; and I’m convinced by their arguments that they cannot emerge from such systems – in other words, from any system based on current computing technology. Steve Grand’s robot “Lucy” will never achieve consciousness.
Will more recent technologies such as biotechnology, nanotechnology and quantum computing ever recreate the equivalent of human experience and behaviour in a way that digital logic and classical physics can’t? Possibly. But any such development would be artificial life, not artificial intelligence. Artificial lifeforms – which in a very simple sense have already been created – could potentially experience the world similarly to us. If they ever become sufficiently sophisticated, then this experience could lead to the emergence of free-will, values and judgements.
But those values would not be our values: they would be based on a different experience of “life” and on empathy between artificial lifeforms, not with us. And there is therefore no guarantee at all that the judgements resulting from those values would be in our interest.
Why Stephen Hawkings, Bill Gates and Elon Musk are wrong about Artificial Intelligence today … but why we should be worried about Artificial Life tomorrow
Recently prominent technologists and scientists such as Stephen Hawking, Elon Musk (founder of PayPal and Tesla) and Bill Gates have spoken out about the danger of Artificial Intelligence, and the likelihood of machines taking over the world from humans. At the MIT Conference last week, Andy McAfee hypothesised that the current concern was caused by the fact that over the last couple of years Artificial Intelligence has finally started to deliver some of the promises it’s been making for the past 50 years.
(Self-replicating cells created from synthetic DNA by scientist Craig Venter)
In reality, these companies are succeeding by avoiding some of the really hard challenges of reproducing human capabilities such as common sense, free will and value-based judgement. They are concentrating instead on making better sense of the physical environment, on processing information in human language, and on creating algorithms that “learn” through feeback loops and self-adjustment.
I think Andy and these experts are right: artificial intelligence has made great strides, but it is not artificial life, and it is a long, long way from creating life-like characteristics such as experience, values and judgements.
If we ever do create artificial life with those characteristics, then I think we will encounter the dangers that Hawkings, Musk and Gates have identified: artificial life will have its own values and act on its own judgement, and any regard for our interests will come second to its own.
That’s a path I don’t think we should go down, and I’m thankful that we’re such a long way from being able to pursue it in anger. I hope that we never do – though I’m also concerned that in Craig Venter and Steve Grand’s work, as well as in robots such as BINA48, we already are already taking the first steps.
But I think in the meantime, there’s tremendous opportunity for digital technology and traditional artificial intelligence to complement human qualities. These technologies are not artificial life and will not overthrow or replace humanity. Hawkings, Gates and Musk are wrong about that.
The human value of the Experience Economy
The final debate at the MIT conference returned to the topic that started the debate over dinner the night before with McAfee and Brynjolfsson: what happens to mass employment in a world where digital technology is automating not just physical work but work involving intelligence and decision-making; and how do we educate today’s children to be successful in a decade’s time in an economy that’s been transformed in ways that we can’t predict?
Andy said we should answer that question by understanding “where will the economic value of humans be?”
I think the answer to that question lies in the experiences that we value emotionally – the experiences digital technology can’t have and can’t understand or replicate; and in the profound differences between the way that humans think and that machines process information.
It’s nearly 20 years since a computer, IBM’s Deep Blue, first beat the human world champion at Chess, Grandmaster Gary Kasparov. But despite the astonishing subsequent progress in computer power, the world’s best chess player is no longer a computer: it is a team of computers and people playing together. And the world’s best team has neither the world’s best computer chess programme nor the world’s best human chess player amongst its members: instead, it has the best technique for breaking down and distributing the thinking involved in playing chess between its human and computer members, recognising that each has different strengths and qualities.
But we’re not all chess experts. How will the rest of us earn a living in the future?
I had the pleasure last year at TEDxBrum of meeting Nicholas Lovell, author of “The Curve“, a wonderful book exploring the effect that digital technology is having on products and services. Nicholas asks – and answers – a question that McAfee and Brynjolfsson also ask: what happens when digital technology makes the act of producing and distributing some products – such as music, art and films – effectively free?
Nicholas’ answer is that we stop valuing the product and start valuing our experience of the product. This is why some musical artists give away digital copies of their albums for free, whilst charging £30 for a leather-bound CD with photographs of stage performances – and whilst charging £10,000 to visit individual fans in their homes to give personal performances for those fans’ families and friends.
We have always valued the quality of such experiences – this is one reason why despite over a century of advances in film, television and streaming video technology, audiences still flock to theatres to experience the direct performance of plays by actors. We can see similar technology-enabled trends in sectors such as food and catering – Kitchen Surfing, for example, is a business that uses a social media platform to enable anyone to book a professional chef to cook a meal in their home.
The “Experience Economy” is a tremendously powerful idea. It combines something that technology cannot do on its own – create experiences based on human value – with many things that almost all people can do: cook, create art, rent a room, drive a car, make clothes or furniture. Especially when these activities are undertaken socially, they create employment, fulfillment and social capital. And most excitingly, technologies such as Cloud Computing, Open Source Software, social media, and online “Sharing Economy” marketplaces such as Etsy make it possible for anyone to begin earning a living from them with a minimum of expense.
I think that the idea of an “Experience Economy” that is driven by the value of inter-personal and social interactions between people, enabled by “Sharing Economy” business models and technology platforms that enable people with a potentially mutual interest to make contact with each other, is an exciting and very human vision of the future.
Even further: because we are physical beings, we tend to value these interactions more when they occur face-to-face, or when they happen in a place for which we share a mutual affiliation. That creates an incentive to use technology to identify opportunities to interact with people with whom we can meet by walking or cycling, rather than requiring long-distance journeys. And that incentive could be an important component of a long-term sustainable economy.
The future our children will choose
(Today’s 5 year-olds are the world’s first generation who grew up teaching themselves to use digital information from anywhere in the world before their parents taught them to read and write)
I’m convinced that the current generation of Artifical Intelligence based on digital technologies – even those that mimic some structures and behaviours of biological systems, such as Steve Grand’s robot Lucy, BINA48 and IBM’s “brain-inspired” True North chip – will not re-create anything we would recognise as conscious life and free will; or anything remotely capable of understanding human values or making judgements that can be relied on to be consistent with them.
But I am also an atheist and a scientist; and I do not believe there is any mystical explanation for our own consciousness and free will. Ultimately, I’m sure that a combination of science, philosophy and human insight will reveal their origin; and sooner or later we’ll develop a technology – that I do not expect to be purely digital in nature – capable of replicating them.
What might we choose to do with such capabilities?
These capabilities will almost certainly emerge alongside the ability to significantly change our physical minds and bodies – to improve brain performance, muscle performance, select the characteristics of our children and significantly alter our physical appearance. That’s why some people are excited by the science fiction-like possibility of harnessing these capabilities to create an “improved” post-human species – perhaps even transferring our personalities from our own bodies into new, technological machines. These are possibilities that I personally find to be at the very least distasteful; and at worst to be inhuman and frightening.
All of these things are partially possible today, and frankly the limit to which they can be explored is mostly a function of the cost and capability of the available techniques, rather than being set by any legislation or mediated by any ethical debate. To echo another theme of discussions at last week’s MIT conference, science and technology today are developing at a pace that far outstrips the ability of governments, businesses, institutions and most individual people to adapt to them.
I have reasonably clear personal views on these issues. I think our lives are best lived relatively naturally, and that they will be collectively better if we avoid using technology to create artificial “improvements” to our species.
But quite apart from the fact that there are any number of enormous practical, ethical and intellectual challenges to my relatively simple beliefs, the raw truth is that it won’t be my decision whether or how far we pursue these possibilities, nor that of anyone else of my generation (and for the record, I am in my mid-forties).
Much has been written about “digital natives” – those people born in the 1990s who are the first generation who grew up with the Internet and social media as part of their everyday world. The way that that generation socialises, works and thinks about value is already creating enormous changes in our world.
But they are nothing compared to the generation represented by today’s very young children who have grown up using touchscreens and streaming videos, technologies so intuitive and captivating that 2-year-olds now routinely teach themselves how to immerse themselves in them long before parents or school teachers teach them how to read and write.
When I was a teenager in the UK, grown-ups wore suits and had traditional haircuts; grown-up men had no earrings. A common parental challenge was to deal with the desire of teenage daughters to have their ears pierced. Those attitudes are terribly old-fashioned today, and our cultural norms have changed dramatically.
I may be completely wrong; but I fully expect our current attitudes to biological and technological manipulation or augmentation of our minds and bodies to thoroughly change over the next few decades; and I have no idea what they will ultimately become. What I do know is that it is likely that my six-year old son’s generation will have far more influence over their ultimate form than my generation will; and that he will grow up with a fundamentally different expectation of the world and his relationship with technology than I have.
I’ve spent my life being excited about technology and the possibilities it creates; ironically I now find myself at least as terrified as I am excited about the world technology will create for my son. I don’t think that my thinking is the result of a mistaken focus on technology over human values – like it or not, our species is differentiated from all others on this planet by our ability to use tools; by our technology. We will not stop developing it.
Our continuing challenge will be to keep a focus on our human values as we do so. I cannot tell my son what to do indefinitely; I can only try to help him to experience and treasure socialising and play in the real world; the experience of growing and preparing food together ; the joy of building things for other people with his own hands. And I hope that those experiences will create human values that will guide him and his generation on a healthy course through a future that I can only begin to imagine.
Why data is uncertain, cities are not programmable, and the world is not “algorithmic”.
Many people are not convinced that the Smart Cities movement will result in the use of technology to make places, communities and businesses in cities better. Outside their consumer enjoyment of smartphones, social media and online entertainment – to the degree that they have access to them – they don’t believe that technology or the companies that sell it will improve their lives.
Most recently, the idea that traditional processes of government should be replaced by “algorithmic regulation” – the comparison of the outcomes of public systems to desired objectives through the measurement of data, and the automatic adjustment of those systems by algorithms in order to achieve them – has been proposed by Tim O’Reilly and other prominent technologists.
These approaches work in many mechanical and engineering systems – the autopilots that fly planes or the anti-lock braking systems that we rely on to stop our cars. But should we extend them into human realms – how we educate our children or how we rehabilitate convicted criminals?
It’s clearly important to ask whether it would be desirable for our society to adopt such approaches. That is a complex debate, but my personal view is that in most cases the incredible technologies available to us today – and which I write about frequently on this blog – should not be used to take automatic decisions about such issues. They are usually more valuable when they are used to improve the information and insight available to human decision-makers – whether they are politicians, public workers or individual citizens – who are then in a better position to exercise good judgement.
More fundamentally, though, I want to challenge whether “algorithmic regulation” or any other highly deterministic approach to human issues is even possible. Quite simply, it is not.
It is true that our ability to collect, analyse and interpret data about the world has advanced to an astonishing degree in recent years. However, that ability is far from perfect, and strongly established scientific and philosophical principles tell us that it is impossible to definitively measure human outcomes from underlying data in physical or computing systems; and that it is impossible to create algorithmic rules that exactly predict them.
Sometimes automated systems succeed despite these limitations – anti-lock braking technology has become nearly ubiquitous because it is more effective than most human drivers at slowing down cars in a controlled way. But in other cases they create such great uncertainties that we must build in safeguards to account for the very real possibility that insights drawn from data are wrong. I do this every time I leave my home with a small umbrella packed in my bag despite the fact that weather forecasts created using enormous amounts of computing power predict a sunny day.
(No matter how sophisticated computer models of cities become, there are fundamental reasons why they will always be simplifications of reality. It is only by understanding those constraints that we can understand which insights from computer models are valuable, and which may be misleading. Image of Sim City by haljackey)
We can only understand where an “algorithmic” approach can be trusted; where it needs safeguards; and where it is wholly inadequate by understanding these limitations. Some of them are practical, and limited only by the sensitivity of today’s sensors and the power of today’s computers. But others are fundamental laws of physics and limitations of logical systems.
A blog published by the highly influential magazine Wired recently made similar overstatements: “The Universe is Programmable” argues that we should extend the concept of an “Application Programming Interface (API)” – a facility usually offered by technology systems to allow external computer programmes to control or interact with them – to every aspect of the world, including our own biology.
To compare complex, unpredictable, emergent biological and social systems to the very logical, deterministic world of computer software is at best a dramatic oversimplification. The systems that comprise the human body range from the armies of symbiotic microbes that help us digest food in our stomachs to the consequences of using corn syrup to sweeten food to the cultural pressure associated with “size 0” celebrities. Many of those systems can’t be well modelled in their own right, let alone deterministically related to each other; let alone formally represented in an accurate, detailed way by technology systems (or even in mathematics).
We should regret and avoid the hubris that leads to the distrust of technology by overstating its capability and failing to recognise its challenges and limitations. That distrust is a barrier that prevents us from achieving the very real benefits that data and technology can bring, and that have been convincingly demonstrated in the past.
For example, an enormous contribution to our knowledge of how to treat and prevent disease was made by John Snow who used data to analyse outbreaks of cholera in London in the 19th century. Snow used a map to correlate cases of cholera to the location of communal water pipes, leading to the insight that water-borne germs were responsible for spreading the disease. We wash our hands to prevent diseases spreading through germs in part because of what we would now call the “geospatial data analysis” performed by John Snow.
Many of the insights that we seek from analytic and smart city systems are human in nature, not physical or mathematical – for example identifying when and where to apply social care interventions in order to reduce the occurrence of emotional domestic abuse. Such questions are complex and uncertain: what is “emotional domestic abuse?” Is it abuse inflicted by a live-in boyfriend, or by an estranged husband who lives separately but makes threatening telephone calls? Does it consist of physical violence or bullying? And what is “bullying”?
We attempt to create structured, quantitative data about complex human and social issues by using approximations and categorisations; by tolerating ranges and uncertainties in numeric measurements; by making subjective judgements; and by looking for patterns and clusters across different categories of data. Whilst these techniques can be very powerful, just how difficult it is to be sure what these conventions and interpretations should be is illustrated by the controversies that regularly arise around “who knew what, when?” whenever there is a high profile failure in social care or any other public service.
These challenges are not limited to “high level” social, economic and biological systems. In fact, they extend throughout the worlds of physics and chemistry into the basic nature of matter and the universe. They fundamentally limit the degree to which we can measure the world, and our ability to draw insight from that information.
By being aware of these limitations we are able to design systems and practises to use data and technology effectively. We know more about the weather through modelling it using scientific and mathematical algorithms in computers than we would without those techniques; but we don’t expect those forecasts to be entirely accurate. Similarly, supermarkets can use data about past purchases to make sufficiently accurate predictions about future spending patterns to boost their profits, without needing to predict exactly what each individual customer will buy.
We underestimate the limitations and flaws of these approaches at our peril. Whilst Tim O’Reilly cites several automated financial systems as good examples of “algorithmic regulation”, the financial crash of 2008 showed the terrible consequences of the thoroughly inadequate risk management systems used by the world’s financial institutions compared to the complexity of the system that they sought to profit from. The few institutions that realised that market conditions had changed and that their models for risk management were no longer valid relied instead on the expertise of their staff, and avoided the worst affects. Others continued to rely on models that had started to produce increasingly misleading guidance, leading to the recession that we are only now emerging from six years later, and that has damaged countless lives around the world.
Every day in their work, scientists, engineers and statisticians draw conclusions from data and analytics, but they temper those conclusions with an awareness of their limitations and any uncertainties inherent in them. By taking and communicating such a balanced and informed approach to applying similar techniques in cities, we will create more trust in these technologies than by overstating their capabilities.
What follows is a description of some of the scientific, philosophical and practical issues that lead inevitability to uncertainty in data, and to limitations in our ability to draw conclusions from it:
But I’ll finish with an explanation of why we can still draw great value from data and analytics if we are aware of those issues and take them properly into account.
1. Heisenberg’s Uncertainty Principle and the fundamental impossibility of knowing everything about anything
Heisenberg’s Uncertainty Principle is a cornerstone of Quantum Mechanics, which, along with General Relativity, is one of the two most fundamental theories scientists use to understand our world. It defines a limit to the precision with which certain pairs of properties of the basic particles which make up the world – such as protons, neutrons and electrons – can be known at the same time. For instance, the more accurately we measure the position of such particles, the more uncertain their speed and direction of movement become.
In order to measure something, we have to interact with it. In everyday life, we do this by using our eyes to measure lightwaves that are created by lightbulbs or the sun and that then reflect off objects in the world around us.
But when we shine light on an object, what we are actually doing is showering it with billions of photons, and observing the way that they scatter. When the object is quite large – a car, a person, or a football – the photons are so small in comparison that they bounce off without affecting it. But when the object is very small – such as an atom – the photons colliding with it are large enough to knock it out of its original position. In other words, measuring the current position of an object involves a collision which causes it to move in a random way.
This analogy isn’t exact; but it conveys the general idea. (For a full explanation, see the figure and link above). Most of the time, we don’t notice the effects of Heisenberg’s Uncertainty Principle because it applies at extremely small scales. But it is perhaps the most fundamental law that asserts that “perfect knowledge” is simply impossible; and it illustrates a wider point that any form of measurement or observation in general affects what is measured or observed. Sometimes the effects are negligible, but often they are not – if we observe workers in a time and motion study, for example, we need to be careful to understand the effect our presence and observations have on their behaviour.
2. Accuracy, precision, noise, uncertainty and error: why measurements are never fully reliable
Outside the world of Quantum Mechanics, there are more practical issues that limit the accuracy of all measurements and data.
(A measurement of the electrical properties of a superconducting device from my PhD thesis. Theoretically, the behaviour should appear as a smooth, wavy line; but the experimental measurement is affected by noise and interference that cause the signal to become “fuzzy”. In this case, the effects of noise and interference – the degree to which the signal appears “fuzzy” – are relatively small compared to the strength of the signal, and the device is usable)
We live in a “warm” world – roughly 300 degrees Celsius above what scientists call “absolute zero“, the coldest temperature possible. What we experience as warmth is in fact movement: the atoms from which we and our world are made “jiggle about” – they move randomly. When we touch a hot object and feel pain it is because this movement is too violent to bear – it’s like being pricked by billions of tiny pins.
This random movement creates “noise” in every physical system, like the static we hear in analogue radio stations or on poor quality telephone connections.
We also live in a busy world, and this activity leads to other sources of noise. All electronic equipment creates electrical and magnetic fields that spread beyond the equipment itself, and in turn affect other equipment – we can hear this as a buzzing noise when we leave smartphones near radios.
Generally speaking, all measurements are affected by random noise created by heat, vibrations or electrical interference; are limited by the precision and accuracy of the measuring devices we use; and are affected by inconsistencies and errors that arise because it is always impossible to completely separate the measurement we want to make from all other environmental factors.
Scientists, engineers and statisticians are familiar with these challenges, and use techniques developed over the course of more than a century to determine and describe the degree to which they can trust and rely on the measurements they make. They do not claim “perfect knowledge” of anything; on the contrary, they are diligent in describing the unavoidable uncertainty that is inherent in their work.
3. The limitations of measuring the natural world using digital systems
One of the techniques we’ve adopted over the last half century to overcome the effects of noise and to make information easier to process is to convert “analogue” information about the real world (information that varies smoothly) into digital information – i.e. information that is expressed as sequences of zeros and ones in computer systems.
(When analogue signals are amplified, so is the noise that they contain. Digital signals are interpreted using thresholds: above an upper threshold, the signal means “1”, whilst below a lower threshold, the signal means “0”. A long string of “0”s and “1”s can be used to encode the same information as contained in analogue waves. By making the difference between the thresholds large compared to the level of signal noise, digital signals can be recreated to remove noise. Further explanation and image by Science Aid)
This process involves a trade-off between the accuracy with which analogue information is measured and described, and the length of the string of digits required to do so – and hence the amount of computer storage and processing power needed.
This trade-off can be clearly seen in the difference in quality between an internet video viewed on a smartphone over a 3G connection and one viewed on a high definition television using a cable network. Neither video will be affected by the static noise that affects weak analogue television signals, but the limited bandwidth of a 3G connection dramatically limits the clarity and resolution of the image transmitted.
The Nyquist–Shannon sampling theorem defines this trade-off and the limit to the quality that can be achieved in storing and processing digital information created from analogue sources. It determines the quality of digital data that we are able to create about any real-world system – from weather patterns to the location of moving objects to the fidelity of sound and video recordings. As computers and communications networks continue to grow more powerful, the quality of digital information will improve, but it will never be a perfect representation of the real world.
Three limits to our ability to analyse data and draw insights from it
1. Gödel’s Incompleteness Theorem and the inconsistency of algorithms
Kurt Gödel’s Incompleteness Theorem sets a limit on what can be achieved by any “closed logical system”. Examples of “closed logical systems” include computer programming languages, any system for creating algorithms – and mathematics itself.
We use “closed logical systems” whenever we create insights and conclusions by combining and extrapolating from basic data and facts. This is how all reporting, calculating, business intelligence, “analytics” and “big data” technologies work.
Gödel’s Incompleteness Theorem proves that any closed logical system can be used to create conclusions that it is not possible to show are true or false using the same system. In other words, whilst computer systems can produce extremely useful information, we cannot rely on them to prove that that information is completely accurate and valid. We have to do that ourselves.
Gödel’s theorem doesn’t stop computer algorithms that have been verified by humans using the scientific method from working; but it does mean that we can’t rely on computers to both generate algorithms and guarantee their validity.
2. The behaviour of many real-world systems can’t be reduced analytically to simple rules
Many systems in the real-world are complex: they cannot be described by simple rules that predict their behaviour based on measurements of their initial conditions.
A simple example is the “three body problem“. Imagine a sun, a planet and a moon all orbiting each other. The movement of these three objects is governed by the force of gravity, which can be described by relatively simple mathematical equations. However, even with just three objects involved, it is not possible to use these equations to directly predict their long-term behaviour – whether they will continue to orbit each other indefinitely, or will eventually collide with each other, or spin off into the distance.
(A computer simulation by Hawk Express of a Belousov–Zhabotinsky reaction, in which reactions between liquid chemicals create oscillating patterns of colour. The simulation is carried out using “cellular automata” a technique based on a grid of squares which can take different colours. In each “turn” of the simulation, like a turn in a board game, the colour of each square is changed using simple rules based on the colours of adjacent squares. Such simulations have been used to reproduce a variety of real-world phenomena)
As Stephen Wolfram argued in his controversial book “A New Kind of Science” in 2002, we need to take a different approach to understanding such complex systems. Rather than using mathematics and logic to analyse them, we need to simulate them, often using computers to create models of the elements from which complex systems are composed, and the interactions between them. By running simulations based on a large number of starting points and comparing the results to real-world observations, insights into the behaviour of the real-world system can be derived. This is how weather forecasts are created, for example.
But as we all know, weather forecasts are not always accurate. Simulations are approximations to real-world systems, and their accuracy is restricted by the degree to which digital data can be used to represent a non-digital world. For this reason, conclusions and predictions drawn from simulations are usually “average” or “probable” outcomes for the system as a whole, not precise predictions of the behaviour of the system or any individual element of it. This is why weather forecasts are often wrong; and why they predict likely levels of rain and windspeed rather than the shape and movement of individual clouds.
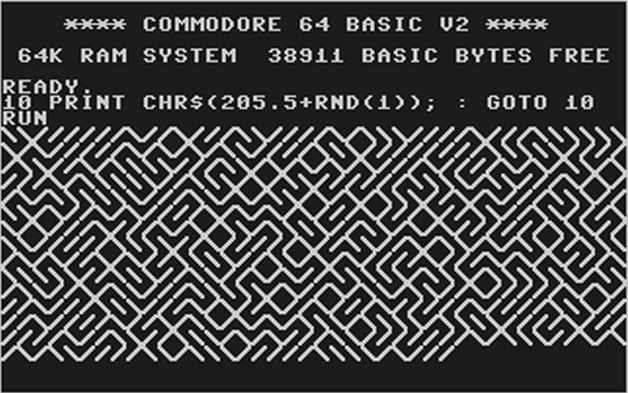
(A simple and famous example of a computer programme that never stops running because it calls itself. The output continually varies by printing out characters based on random number generation. Image by Prosthetic Knowledge)
3. Some problems can’t be solved by computing machines
If I consider a simple question such as “how many letters are in the word ‘calculation’?”, I can easily convince myself that a computer programme could be written to answer the question; and that it would find the answer within a relatively short amount of time. But some problems are much harder to solve, or can’t even be solved at all.
For example, a “Wang Tile” (see image below) is a square tile formed from four triangles of different colours. Imagine that you have bought a set of tiles of various colour combinations in order to tile a wall in a kitchen or bathroom. Given the set of tiles that you have bought, is it possible to tile your wall so that triangles of the same colour line up to each other, forming a pattern of “Wang Tile” squares?
In 1966 Robert Berger proved that no algorithm exists that can answer that question. There is no way to solve the problem – or to determine how long it will take to solve the problem – without actually solving it. You just have to try to tile the room and find out the hard way.
One of the most famous examples of this type of problem is the “halting problem” in computer science. Some computer programmes finish executing their commands relatively quickly. Others can run indefinitely if they contain a “loop” instruction that never ends. For others which contain complex sequences of loops and calls from one section of code to another, it may be very hard to tell whether the programme finishes quickly, or takes a long time to complete, or never finishes its execution at all.
(A set of Wang Tiles, and a pattern of coloured squares created by tiling them. Given any random set of tiles of different colour combinations, there is no set of rules that can be relied on to determine whether a valid pattern of coloured squares can be created from them. Sometimes, you have to find out by trial and error. Images from Wikipedia)
Five reasons why the human world is messy, unpredictable, and can’t be perfectly described using data and logic
1. Our actions create disorder
The 2nd Law of Thermodynamics is a good candidate for the most fundamental law of science. It states that as time progresses, the universe becomes more disorganised. It guarantees that ultimately – in billions of years – the Universe will die as all of the energy and activity within it dissipates.
For example, if I spend a day building a shed, then to create that order and value from raw materials, I consume structured food and turn it into sewage. Or if I use an electric forklift to stack a pile of boxes, I use electricity that has been created by burning structured coal into smog and ash.
So it is literally impossible to create a “perfect world”. Whenever we act to make a part of the world more ordered, we create disorder elsewhere. And ultimately – thankfully, long after you and I are dead – disorder is all that will be left.
2. The failure of Logical Atomism: why the human world can’t be perfectly described using data and logic
In the 20th Century two of the most famous and accomplished philosophers in history, Bertrand Russell and Ludwig Wittgenstein, invented “Logical Atomism“, a theory that the entire world could be described by using “atomic facts” – independent and irreducible pieces of knowledge – combined with logic.
But despite 40 years of work, these two supremely intelligent people could not get their theory to work: “Logical Atomism” failed. It is not possible to describe our world in that way.
One cause of the failure was the insurmountable difficulty of identifying truly independent, irreducible atomic facts. “The box is red” and “the circle is blue”, for example, aren’t independent or irreducible facts for many reasons. “Red” and “blue” are two conventions of human language used to describe the perceptions created when electro-magnetic waves of different frequencies arrive at our retinas. In other words, they depend on and relate to each other through a number of sophisticated systems.
Despite centuries of scientific and philosophical effort, we do not have a complete understanding of how to describe our world at its most basic level. As physicists have explored the world at smaller and smaller scales, Quantum Mechanics has emerged as the most fundamental theory for describing it – it is the closest we have come to finding the “irreducible facts” that Russell and Wittgenstein were looking for. But whilst the mathematical equations of Quantum Mechanics predict the outcomes of experiments very well, after nearly a century, physicists still don’t really agree about what those equations mean. And as we have already seen, Heisenberg’s Uncertainty Principle prevents us from ever having perfect knowledge of the world at this level.
Perhaps the most important failure of logical atomism, though, was that it proved impossible to use logical rules to turn “facts” at one level of abstraction – for example, “blood cells carry oxygen”, “nerves conduct electricity”, “muscle fibres contract” – into facts at another level of abstraction – such as “physical assault is a crime”. The human world and the things that we care about can’t be described using logical combinations of “atomic facts”. For example, how would you define the set of all possible uses of a screwdriver, from prising the lids off paint tins to causing a short-circuit by jamming it into a switchboard?
Our world is messy, subjective and opportunistic. It defies universal categorisation and logical analysis.
(A Pescheria in Bari, Puglia, where a fish-market price information service makes it easier for local fisherman to identify the best buyers and prices for their daily catch. Photo by Vito Palmi)
3. The importance and inaccessibility of “local knowledge”
Because the tool we use for calculating and agreeing value when we exchange goods and services is money, economics is the discipline that is often used to understand the large-scale behaviour of society. We often quantify the “growth” of society using economic measures, for example.
But this approach is notorious for overlooking social and environmental characteristics such as health, happiness and sustainability. Alternatives exist, such as the Social Progress Index, or the measurement framework adopted by the United Nations 2014 Human Development Report on world poverty; but they are still high level and abstract.
Such approaches struggle to explain localised variations, and in particular cannot predict the behaviours or outcomes of individual people with any accuracy. This “local knowledge problem” is caused by the fact that a great deal of the information that determines individual actions is personal and local, and not measurable at a distance – the experienced eye of the fruit buyer assessing not just the quality of the fruit but the quality of the farm and farmers that produce it, as a measure of the likely consistency of supply; the emotional attachments that cause us to favour one brand over another; or the degree of community ties between local businesses that influence their propensity to trade with each other.
“Sharing economy” business models that use social media and reputation systems to enable suppliers and consumers of goods and services to find each other and transact online are opening up this local knowledge to some degree. Local food networks, freecycling networks, and land-sharing schemes all use this technology to the benefit of local communities whilst potentially making information about detailed transactions more widely available. And to some degree, the human knowledge that influences how transactions take place can be encoded in “expert systems” which allow computer systems to codify the quantitative and heuristic rules by which people take decisions.
But these technologies are only used in a subset of the interactions that take place between people and businesses across the world, and it is unlikely that they’ll become ubiquitous in the foreseeable future (or that we would want them to become so). Will we ever reach the point where prospective house-buyers delegate decisions about where to live to computer programmes operating in online marketplaces rather than by visiting places and imagining themselves living there? Will we somehow automate the process of testing the freshness of fish by observing the clarity of their eyes and the freshness of their smell before buying them to cook and eat?
In many cases, while technology may play a role introducing potential buyers and sellers of goods and services to each other, it will not replace – or predict – the human behaviours involved in the transaction itself.
(Medway Youth Trust use predictive and textual analytics to draw insight into their work helping vulnerable children. They use technology to inform expert case workers, not to take decisions on their behalf.)
4. “Wicked problems” cannot be described using data and logic
Despite all of the challenges associated with problems in mathematics and the physical sciences, it is nevertheless relatively straightforward to frame and then attempt to solve problems in those domains; and to determine whether the resulting solutions are valid.
As the failure of Logical Atomism showed, though, problems in the human domain are much more difficult to describe in any systematic, complete and precise way – a challenge known as the “frame problem” in artificial intelligence. This is particularly true of “wicked problems” – challenges such as social mobility or vulnerable families that are multi-faceted, and consist of a variety of interdependent issues.
Take job creation, for example. Is that best accomplished through creating employment in taxpayer-funded public sector organisations? Or by allowing private-sector wealth to grow, creating employment through “trickle-down” effects? Or by maximising overall consumer spending power as suggested by “middle-out” economics? All of these ideas are described not using the language of mathematics or other formal logical systems, but using natural human language which is subjective and inconsistent in use.
The failure of Logical Atomism to fully represent such concepts in formal logical systems through which truth and falsehood can be determined with certainty emphasises what we all understand intuitively: there is no single “right” answer to many human problems, and no single “right” action in many human situations.
(An electricity bill containing information provided by OPower comparing one household’s energy usage to their neighbours. Image from Grist)
5. Behavioural economics and the caprice of human behaviour
“Behavioural economics” attempts to predict the way that humans behave when taking choices that have a measurable impact on them – for example, whether to put the washing machine on at 5pm when electricity is expensive, or at 11pm when it is cheap.
But predicting human behaviour is notoriously unreliable.
These are impressive achievements; but they are not always repeatable. A recycling scheme in the UK that adopted a similar approach found instead that it lowered recycling rates across the community: households who learned that they were putting more effort into recycling than their neighbours asked themselves “if my neighbours aren’t contributing to this initiative, then why should I?”
Low carbon engineering technologies like electric vehicles have clearly defined environmental benefits and clearly defined costs. But most Smart Cities solutions are less straightforward. They are complex socio-technical systems whose outcomes are emergent. Our ability to predict their performance and impact will certainly improve as more are deployed and analysed, and as University researchers, politicians, journalists and the public assess them. But we will never predict individual actions using these techniques, only the average statistical behaviour of groups of people. This can be seen from OPower’s own comparison of their predicted energy savings against those actually achieved – the predictions are good, but the actual behaviour of OPower’s customers shows a high degree of apparently random variation. Those variations are the result of the subjective, unpredictable and sometimes irrational behaviour of real people.
We can take insight from Behavioural Economics and other techniques for analysing human behaviour in order to create appropriate strategies, policies and environments that encourage the right outcomes in cities; but none of them can be relied on to give definitive solutions to any individual person or situation. They can inform decision-making, but are always associated with some degree of uncertainty. In some cases, the uncertainty will be so small as to be negligible, and the predictions can be treated as deterministic rules for achieving the desired outcome. But in many cases, the uncertainty will be so great that predictions can only be treated as general indications of what might happen; whilst individual actions and outcomes will vary greatly.
(Of course it is impossible to predict individual criminal actions as portrayed in the film “Minority Report”. But is is very possible to analyse past patterns of criminal activity, compare them to related data such as weather and social events, and predict the likelihood of crimes of certain types occurring in certain areas. Cities such as Memphis and Chicago have used these insights to achieve significant reductions in crime)
Learning to value insight without certainty
Mathematics and digital technology are incredibly powerful; but they will never perfectly and completely describe and predict our world in human terms. In many cases, our focus for using them should not be on automation: it should be on the enablement of human judgement through better availability and communication of information. And in particular, we should concentrate on communicating accurately the meaning of information in the context of its limitations and uncertainties.
There are exceptions where we automate systems because of a combination of a low-level of uncertainty in data and a large advantage in acting autonomously on it. For example, anti-lock braking systems save lives by using automated technology to take thousands of decisions more quickly than most humans would realise that even a single decision needed to be made; and do so based on data with an extremely low degree of uncertainty.
But the most exciting opportunity for us all is to learn to become sophisticated users of information that is uncertain. The results of textual analysis of sentiment towards products and brands expressed in social media are far from certain; but they are still of great value. Similar technology can extract insights from medical research papers, case notes in social care systems, maintenance logs of machinery and many other sources. Those insights will rarely be certain; but properly assessed by people with good judgement they can still be immensely valuable.
This is a much better way to understand the value of technology than ideas like “perfect knowledge” and “algorithmic regulation”. And it is much more likely that people will trust the benefits that we claim new technologies can bring if we are open about their limitations. People won’t use technologies that they don’t trust; and they won’t invest their money in them or vote for politicians who say they’ll spend their taxes on it.
Thankyou to Richard Brown and Adrian McEwen for discussions on Twitter that helped me to prepare this article. A more in-depth discussion of some of the scientific and philosophical issues I’ve described, and an exploration of the nature of human intelligence and its non-deterministic characteristics, can be found in the excellent paper “Answering Descartes: Beyond Turing” by Stuart Kauffman published by MIT press.
(A US Department of Agriculture inspector examines a shipment of imported frozen meat in New Orleans in 2013. Photo by Anson Eaglin)
One of the biggest challenges associated with the rapid urbanisation of the world’s population is working out how to feed billions of extra citizens. I’m spending an increasing amount of my time understanding how technology can help us to do that.
It’s well known that the populations of many of the world’s developing nations – and some of those that are still under-developed – are rapidly migrating from rural areas to cities. In China, for example, hundreds of millions of people are moving from the countryside to cities, leaving behind a lifestyle based on extended family living and agriculture for employment in business and a more modern lifestyle.
The definitions of “urban areas” used in many countries undergoing urbanisation include a criterion that less than 50% of employment and economic activity is based on agriculture (the appendices to the 2007 revision of the UN World Urbanisation Prospects summarise such criteria from around the world). Cities import their food.
In the developed countries of the Western world, this criterion is missing from most definitions of cities, which focus instead on the size and density of population. In the West, the transformation of economic activity away from agriculture took place during the Industrial Revolution of the 18th and 19th Centuries.
Urbanisation and the industrialisation of food
The food that is now supplied to Western cities is produced through a heavily industrialised process. But whilst the food supply chain had to scale dramatically to feed the rapidly growing cities of the Industrial Revolution, the processes it used, particularly in growing food and creating meals from it, did not industrialise – i.e. reduce their dependence on human labour – until much later.
As described by Population Matters, industrialisation took place after the Second World War when the countries involved took measures to improve their food security after struggling to feed themselves during the War whilst international shipping routes were disrupted. Ironically, this has now resulted in a supply chain that’s even more internationalised than before as the companies that operate it have adopted globalisation as a business strategy over the last two decades.
This industrial model has led to dramatic increases in the quantity of food produced and distributed around the world, as the industry group the Global Harvest Initiative describes. But whether it is the only way, or the best way, to provide food to cities at the scale required over the next few decades is the subject of much debate and disagreement.
(Irrigation enables agriculture in the arid environment of Al Jawf, Libya. Photo by Future Atlas)
One of the critical voices is Philip Lymbery, the Chief Executive of Compassion in World Farming, who argues passionately in “Farmageddon” that the industrial model of food production and distribution is extremely inefficient and risks long-term damage to the planet.
Lymbery questions whether the industrial system is sustainable financially – it depends on vast subsidy programmes in Europe and the United States; and he questions its social benefits – industrial farms are highly automated and operate in formalised international supply chains, so they do not always provide significant food or employment in the communities in which they are based.
He is also critical of the industrial system’s environmental impact. In order to optimise food production globally for financial efficiency and scale, single-use industrial farms have replaced the mixed-use, rotational agricultural systems that replenish nutrients in soil and that support insect species that are crucial to the pollination of plants. They also create vast quantities of animal waste that causes pollution because in the single-use industrial system there are no local fields in need of manure to fertilise crops.
And the challenges associated with feeding the growing populations of the worlds’ cities are not only to do with long-term sustainability. They are also a significant cause of ill-health and social unrest today.
But increasing the amount of food available to feed people doesn’t necessarily mean growing more food, either by further intensifying existing industrial approaches or by adopting new techniques such as vertical farming or hydroponics. In fact, a more recent report issued by the United Nations and partner agencies cautioned that it was unlikely that the necessary increase in available food would be achieved through yield increases alone. Instead, it recommended reducing food loss, waste, and “excessive demand” for animal products.
I think that technology has some exciting roles to play in how we respond to those challenges.
Smarter food in the field: data for free, predicting the future and open source beekeeping
New technologies give us a great opportunity to monitor, measure and assess the agricultural process and the environment in which it takes place.
The SenSprout sensor can measure and transmit the moisture content of soil; it is made simply by printing an electronic circuit design onto paper using commercially-available ink containing silver nano-particles; and it powers itself using ambient radio waves. We can use sensors like SenSprout to understand and respond to the natural environment, using technology to augment the traditional knowledge of farmers.
These possibilities are not limited to industrial agriculture or to developed countries. For example, the Kilimo Salama scheme adds resilience to the traditional practises of subsistence farmers by using remote weather monitoring and mobile phone payment schemes to provide affordable insurance for their crops.
Smarter food in the marketplace: local food, the sharing economy and soil to fork traceability
The emergence of the internet as a platform for enabling sales, marketing and logistics over the last decade has enabled small and micro-businesses to reach markets across the world that were previously accessible only to much larger organisations with international sales and distribution networks. The proliferation of local food and urban farming initiatives shows that this transformation is changing the food industry too, where online marketplaces such as Big Barn and FoodTrade make it easier for consumers to buy locally produced food, and for producers to sell it.
This is not to say that vast industrial supply-chains will disappear overnight to be replaced by local food networks: they clearly won’t. But just as large-scale film and video production has adapted to co-exist and compete with millions of small-scale, “long-tail” video producers, so too the food industry will adjust. The need for co-existence and competition with new entrants should lead to improvements in efficiency and impact – the supermarket Tesco’s “Buying Club” shows how one large food retailer is already using these ideas to provide benefits that include environmental efficiences to its smaller suppliers.
(A Pescheria in Bari, Puglia photographed by Vito Palmi)
One challenge is that food – unlike music and video – is a fundamentally physical commodity: exchanging it between producers and consumers requires transport and logistics. The adoption by the food industry of “sharing economy” approaches – business models that use social media and analytics to create peer-to-peer transactions, and that replace bulk movement patterns by thousands of smaller interactions between individuals – will be dependent on our ability to create innovative distribution systems to support them. Zaycon Foods operate one such system, using online technology to allow consumers to collectively negotiate prices for food that they then collect from farmers at regular local events.
Rather than replacing existing markets and supply chains, one role that technology is already playing is to give food producers better insight into their behaviour. M-farm links farmers in Kenya to potential buyers for their produce, and provides them with real-time information about prices; and the University of Bari in Puglia, Italy operates a similar fish-market pricing information service that makes it easier for local fisherman to identify the best buyers and prices for their daily catch.
This advice from the Mayo Clinic in the United States gives one example of the link between the provenance of food and its health qualities, explaining that beef from cows fed on grass can have lower levels of fat and higher levels of beneficial “omega-3 fatty acids” than what they call “conventional beef” – beef from cows fed on grain delivered in lorries. (They appear to have forgotten the “convention” established by several millennia of evolution and thousands of years of animal husbandry that cows eat grass).
(Baltic Apple Pie – a recipe created by IBM’s Watson computer)
All of this information contributes to describing both the taste and health characteristics of food; and when it’s available, we’ll have the opportunity to make more informed choices about what we put on our tables.
Smarter food in the kitchen: cooking, blogging and cognitive computing
But whilst eating less meat and more fish and vegetables is a simple idea, putting it into practise is a complex cultural challenge.
A recent report found that “a third of UK adults struggle to afford healthy food“. But the underlying cause is not economic: it is a lack of familiarity with the cooking and food preparation techniques that turn cheap ingredients into healthy, tasty food; and a cultural preference for red meat and packaged meals. The Sustainable Food School that is under development in Birmingham is one example of an initiative intending to address those challenges through education and awareness.
Engagement through traditional and social media also has an influence. The celebrity chefs that have campaigned for a shift in our diets towards more sustainably sourced fish and the schoolgirl who provoked a national debate concerning the standard and health of school meals simply by blogging about the meals that were offered to her each day at school, are two recent examples in the UK; as is the food blogger Jack Monroe who demonstrated how she could feed herself and her two-year-old son healthy, interesting food on a budget of £10 a week.
My colleagues in IBM Research have explored turning IBM’s Watson cognitive computing technology to this challenge. In an exercise similar to the “invention test” common to television cookery competitions, they have challenged Watson to create recipes from a restricted set of ingredients (such as might be left in the fridge and cupboards at the end of the week) and which meet particular criteria for health and taste.
(An example of local food processing: my own homemade chorizo.)
Food, technology, passion
The future of food is a complex and contentious issue – the controversy between the productivity benefits of industrial agriculture and its environmental and social impact being just one example. I have touched on but not engaged in those debates in this article – my expertise is in technology, not in agriculture, and I’ve attempted to link to a variety of sources from all sides of the debate.
Some of the ideas for providing food to the world’s growing population in the future are no less challenging, whether those ideas are cultural or technological. The United Nations suggested last year, for example, that more of us should join the 2 billion people who include insects in their diet. Insects are a nutritious and environmentally efficient source of food, but those of us who have grown up in cultures that do not consider them as food are – for the most part – not at all ready to contemplate eating them. Artificial meat, grown in laboratories, is another increasingly feasible source of protein in our diets. It challenges our assumption that food is natural, but has some very reasonable arguments in its favour.
It’s a trite observation, but food culture is constantly changing. My 5-year-old son routinely demands foods such as humus and guacamole that are unremarkable now but that were far from commonplace when I was a child. Ultimately, our food systems and diets will have to adapt and change again or we’ll run out of food, land and water.
There are no simple answers, but we are all increasingly informed and well-intentioned. And as technology continues to evolve it will provide us with incredible new tools. Those are great ingredients for an “invention test” for us all to find a sustainable, healthy and tasty way to feed future cities.
(The White Horse Tavern in Greenwich Village, New York, one of the city’s oldest taverns. The rich urban life of the Village was described by one of the Taverns’ many famous patrons, the urbanist Jane Jacobs. Photo by Steve Minor).
I’ve spent a lot of time over the past few years discussing the evolution of cities, and the role of technology in that evolution, with architects, social scientists, politicians and academics. In the course of those discussions, every few weeks someone has suggested that Jane Jacobs laid the basic groundwork for understanding that evolution in her 1961 book “The Death and Life of Great Amercian Cities“.
That book is more than half a century old now, and clearly it was written in the context of the technologies of the time. And those technologies are a background presence in it, not it’s focus. But in the sense that construction technologies, transport technologies and digital technologies are only effective in cities when they are subservient to the needs of the everyday lives of people and communities, then Jacobs’ discourse on the proper understanding of those lives remains highly relevant; and should be inspirational to us in understanding how today’s technologies can serve them.
In particular, it is relevant to one of the great societal, ethical, political, legal and technical challenges of our time: privacy in a world of digital information.
The concept of privacy was central to Jacobs’ analysis of the functioning of cities. Her defining characteristic of cities is that the great size of their populations means that most people in them are strangers to each other; and that creating safety and security in that context is very different to creating it a town or village where a higher proportion of people are known to each other.
Her assertion was that cities are safe places for strangers to inhabit or visit when public and private life are clearly separated. When public life is lived on streets with a mixture of residential, retail, work and leisure activities, then those streets are busy at most times of day and night. They are therefore full of observers who inhibit anti-social behaviour, and can intervene to prevent it if necessary. In contrast, private life is safe when it is lived securely and separate from those public spaces, so that strangers cannot intrude.
Places that blur these distinctions can be dangerous. Parks in sparsely populated and entirely residential suburbs, for example, are short of observers; so that if the play of children, or the behaviour of others towards them, becomes threatening, there is less likelihood of a preventive intervention.
This thinking was brought to mind this week by Jan Chipchase’s discussion of the implications of Google Glass. Glass is a “wearable computer” mounted on false spectacles that displays information to overlay what we see. It can make video and audio recordings of the world we are experiencing, and can distribute those recordings through wireless connectivity to the internet. It responds to a voice-control interface and by recognising manual gestures.
Chipchase compared the implications of these capabilities to our assumptions of what constitutes reasonable public behaviour. Is it acceptable that strangers in the same place should record each other’s behaviour and distribute those recordings with no indication that they are doing so? Chipchase suggested that to do so would create distrust and uneasiness in public situations.
Such unsignalled recording and distribution of public behaviour blurs boundaries between new forms of public and private context. In a physically public context, an individual is privately choosing to distribute detailed information concerning other individuals in that context to a much broader audience who are unknown to the subjects of the recording.
These public and private contexts are related to and extend those that Jacobs discussed; does blurring the boundaries between them undermine safety between strangers in an analogous way?
Suppose I have a conversation with a friend in a cafe about a birthday gift for my wife. If, unknown to us, that conversation is recorded and uploaded to the internet, what is the risk that my wife might discover the nature of what is intended to be a surprise gift?
If the recording is uploaded to Youtube and identified only with a time and a place, my wife is unlikely to stumble across it. But if it is uploaded to a Facebook group concerned with our local highstreet; and if it is tagged with the names of people, places and things extracted by speech-recognition technology from it’s audio content; and if it is recorded by a person who is related by friend-of-a-friend relationship to either me or my wife; then the chance of her encountering it through her own interactions with social media increases.
This is a fairly innocuous example – life is more pleasant when birthday presents are surprises, but it is hardly life-threatening when they are not. But there are many scenarios in which failures of privacy are harmful; and sometimes extremely so.
Chipchase suggested principles of behaviour for avoiding such failures – for example, ways in which Glass users could make it visibly clear to others in their vicinity that they are making a recording. Indeed, many photographers already make a point of establishing the consent of the people they are photographing; the failure of some “Paparazzi” to do so is what leads to the controversies concerning their behaviour.
This discussion is not intended as a criticism of Google Glass. On the contrary, I’m tremendously excited by it’s potential – I’ve written frequently on this blog about the astonishing possibilities that such technologies will create as they remove the boundary between human behaviour and information systems. But we do need take their implications seriously.
And while Glass is still a relatively narrowly distributed prototype, the humble smartphone and related technologies raise similar challenges. They have already fundamentally changed the relationships between our communications with other people, and our proximity to them.
If we use a relatively inconspicuous Bluetooth headset to make a call through a mobile phone hidden in a pocket; and if we gesture with our arms emphatically whilst speaking on that call; how should the people around us, who might be completely unaware that the call is taking place, interpret our actions? And what happens if they perceive those gestures to be rude or threatening?
Our use of such devices already creates a mass of data that diffuses into the world around us. Sometimes this is as a result of deliberate actions: when we share geo-tagged photos through social media, for example.
In other cases, it is incidental. The location and movement of GPS sensors in our smartphones is anonymised by our network providers and aggregated with that of others nearby who are moving similarly. It is then sold to traffic information services, so that they can sell it back to us through the satellite navigation systems in our cars to help us to avoid traffic congestion.
As a result, two of the most frequent questions I am asked in panel debates or media interviews are: who owns all this data? And are big corporations using it and controlling it for their own purposes?
The answers to those questions are not simple, but they are important. Just as Jane Jacobs argued that the provision of privacy in urban environments is fundamental to their ability to successfully support all of their inhabitants; so privacy in digital environments is fundamental to the ability of all of us to benefit fairly from the information economy.
It is certainly true that organisations of all types and sizes are competing for the new markets and opportunities of the information economy that are created, in part, by the increased availability of personal information. That is simply the natural consequence of the emergence of a new resource in a competitive economy. But it is also true that as the originators of much of that information, and as the ultimate stakeholders in that economy, we should seek to establish an equitable consensus between us for how our information is used.
Max Barry’s novel “Jennifer Government” describes a world in which personal information is dominated by loyalty-card programmes that define not just the retail economy, but society as a whole – to the extent to which surnames have been replaced with institutional affiliations (hence the book is populated by characters such as Jennifer “Government”, John “Nike” and Violet “ExxonMobil”). It is simultaneously funny and scary because it is recognisable as one possible extrapolation from the world we live in today (though not, I hope, the most likely; and I should state that Nike and ExxonMobil feature in it in entirely fictitious roles).
A real information-based enterprise working to a different set of principles is MyDex, a Community Interest Company (CIC) who have created a platform for securely storing and sharing personal information. Incorporation as a CIC allows MyDex:
“… to be sustainable and requires it be run for community benefit. Crucially, the CIC assets and the majority of any profits must be used for the community purposes for which Mydex is established. Its assets cannot be acquired by another party to which such restrictions do not apply.”
As a result of both the security of their technology solution and the clarity with which personal and community interests are reflected in their business model, MyDex’s platform is now being used by a variety of public sector and community organisations to offer a personal data store to the people they support.
Mydex’s business structure reflects principles which occur elsewhere in examples of commercial organisations whose operations are consistent with long-term community value.
(Hancock Bank’s vault, damaged by Hurricane Katrina. Photo by Social Stratification)
In Resilience, Andrew Zolli gives another example, that of Hancock Bank’s response to hurricane katrina. Hancock are a local institution in New Orleans, and their branch network was 90% destroyed by the hurricane. Whilst they recovered their central systems relatively quickly, without a branch network there was no way to interact with their customers – the citizens of a devastated city with a desperate need for cash to purchase food and basic supplies.
Hancock’s staff were able to set up temporary facilities to meet customers, but without any connection from those facilities to their central systems, how could they know who their customers were, let alone how much money each had in their current account?
Hancock answered this challenge by referring to it’s original charter, which described the bank as an institution that supported the city’s community – not as one which existed to make profits. On that basis they decided to lend $200 to anyone who would write their name and social security number on a piece of paper and sign it.
This astonishing action put desperately needed cash into the community. And the community remembered. After three years all but $250,000 of the $42,000,000 the bank lent in this way had been repaid; and the bank had 13,000 new customer accounts and a $1.5billion increase in deposits. Ultimately, their actions made very good business sense.
So how can we influence institutions to create strategies to deal with our personal information that are similarly consistent with long-term mutual benefit?
In Collapse, Jared Diamond explores at length the role of corporations, consumers, communities, campaigners and political institutions in influencing whether businesses such as fishing and resource extraction are operated in the long term interests of the ecosystem containing them – including their communities, environment and ecology – or whether they are being optimised only for short term financial gain and potentially creating damaging impacts as a consequence.
Diamond asserted that in principle a constructive, sustainable relationship between such businesses and their ecosystems is perfectly compatible with business interest; and in fact is vital to sustaining long-term, profitable business operations. He described at length Chevron’s operations in the Kutubu oilfield in Papua New Guinea, working in partnership with local communities to achieve social, environmental and business sustainability. The World Resources Institute’s recent report, “Aligning profit and environmental sustainability: stories from industry” contains many other examples.
Collapse was written 8 years ago now; and it’s messages on how to influence the sustainability agenda of businesses in the last decade may provide insight into how we should influence the privacy agenda today. In Diamond’s view, the key was to understand where we as consumers can bring the most pressure to bear in the supply chains and markets which depend ultimately on the resources we care about. In Diamond’s words:
“… the most effective pressure on mining companies to change their practises has come not from individual consumers picketing mine sites, but from big companies that buy metals … and that sell to individual consumers”.
As well as applying pressure to those elements in the supply chain where consumers have purchasing power, some means are needed to monitor the behaviour of businesses and certify their performance. Schemes offering such certifications include those operated by the Forestry Stewardship Council for sustainable forestry; BREEAM for sustainable buildings and Fairtrade for socially sustainable food.
There are, of course, significant challenges with this approach: who defines how the impact of resource usage should be measured? Who performs the measurement? Are systems in place across supply chains to track the movement of resources through them such that accurate, end-to-end measurements can be made?
Whilst some of these challenges can be addressed with technology solutions – such as the tracking of food through the supply chain using RFID tags – some of them will only be addressed by informed consumers. Standards for measuring impact, for example, are often defined by non-governmental organisations; and their stakeholders usually include communities, consumers and businesses with an interest in the systems being measured. Typically, several such standards compete in any industry, offering different approaches to measurement. To understand what those standards are telling us; and to use them to choose products and services that promote the outcomes that matter to us, we need to be informed, not casual, consumers.
The lesson for privacy is that all of us need to be sophisticated guardians of our own security – just as we have become more sophisticated purchasers of food and users of technology. We need to exercise that sophistication in choosing to engage with organisations whose approaches to the security and privacy of our data is respectful and transparent, and which build a relationship or transaction of mutual value.
Conversely, we need to help organisations – public or private – that use personal data to understand what for us constitutes the mistreatment of data; especially through actions that are a side effect of our direct transactions with them, akin to the environmental impact of resource industries. And where there is no choice, or no transparency to enable choice, we need to lobby politicians to make clear that we care about these issues, and that we will vote for those who address them.
Of course the security agenda in a digital age is not a new one; but as technology spreads further and deeper into city systems, and into our interactions in city environments, it is useful to bear in mind the enduring legacy of Jane Jacob’s work, and be reminded that security is at the heart of cities, not just technology.
Technology is changing how we understand cities, and how we will understand ourselves in the context of urban environments. We’re only at the beginning of this complex revolution.
Consider that scientists from Berkeley have used a Magnetic Resonance Imaging (MRI) scanner to reconstruct images perceived by a test subject’s brain activity while the subject watched a video. A less sensitive mind-reading technology is already available as a headset from Emotiv. (My colleagues have used Emotiv to help a paralysed person communicate by sending directional instructions from his thoughts to a computer.)
Developments in biotechnology, nanotechnology, and advanced manufacturing show similarly remarkable interactions between information systems and the physical and biological world: solar panels that can mend themselves; living biological tissues that can be printed.
These technologies, combined with our ability to process and draw insight from digital information, could offer real possibilities to engineer more efficient and sustainable city systems, such as transportation, energy, water, and food. But using them to address the demographic, financial, and environmental challenges of cities will raise questions about our relationship with the natural world, what it means to live in an ethical society, and what defines us as human.
(The remainder of this article, which explores ways in which we might answer those questions, can be found on UBM’s Future Cities site, as “Make Way for Sensitive Cities“).
(Akihabara Street in Tokyo, a centre of high technology, photographed by Trey Ratcliff)
A great many factors will determine the future of our cities – for example, human behaviour, demographics, economics, and evolving thinking in urban planning and architecture.
The specific terms “Smart Cities” and “Smarter Cities”, though, are commonly applied to the concept that cities can exploit technology to find new ways to face their challenges. Boyd Cohen of Fast Company offered a useful definition in his article “The Top 10 Smart Cities On The Planet“:
“Smart cities use information and communication technologies (ICT) to be more intelligent and efficient in the use of resources, resulting in cost and energy savings, improved service delivery and quality of life, and reduced environmental footprint–all supporting innovation and the low-carbon economy.”
So what are the technologies that will make cities Smart?
To answer that question, we need to examine the convergence of two domains of staggering complexity, and of which the outcomes are hard to predict.
The first is the domain of cities: vast, overlapping systems of systems. Their behaviour is the aggregated behaviour of their hundreds of thousands or millions of citizens. Whilst early work is starting to understand the relationship between those systems in a quantitative and deterministic way, such as the City Protocol initiative, we are just at the start of that journey.
(An early example of the emerging technologies that are blurring the boundary between the physical world and information: Professor Kevin Warwick, who in 2002 embedded a silicon chip with 100 spiked electrodes directly into his nervous system. Photo by M1K3Y)
If we define a “new form of communication” as a means of enabling new patterns of exchange of information between individuals, rather than as a new underlying infrastructure, then we are inventing them – such as foursquare, StumbleUpon, and Pinterest – at a faster rate than at any previous time in history.
My own profession is information technology; and I spend much of my time focussed on the latest developments in that field. But in the context of cities, it is a relatively narrow domain. More broadly, developments in many disciplines of science, engineering and technology offer new possibilities for cities of the future.
I find the following framework useful in understanding the various engineering, information and communication technologies that can support Smart City projects. As with the other articles I post to this blog, this is not intended to be comprehensive or definitive – it’s far too early in the field for that; but I hope it is nevertheless a useful contribution.
And I will also find a place in it for one of the oldest and most important technologies that our species has invented: language; and it’s exploitation in “Smart” systems such as pens, paper and conversations.
1. Re-engineering the physical components of city systems
(Kohei Hayamizu’s first attempt to capture energy from pedestrian footfall in Shibuya, Tokyo)
The machinery that supports city systems generally converts raw materials and energy into some useful output. The efficiency of that machinery is limited by theory and engineering. The theoretical limit is created by the fact that machinery operates by transforming energy from one form – such as electricity – into another form – such as movement or heat. Physical laws, such as the Laws of Thermodynamics, limit the efficiency of those processes.
For example, the efficiency of a refrigerator is limited by the fact that it will always use some energy to create a temperature gradient in order that heat can be removed from the contents of the fridge; it then requires additional energy to actually perform that heat removal. Engineering challenges then further reduce efficiency – in the example of the fridge, because its moving components create heat and noise.
One way to improve the efficiency of city systems is to improve the efficiency of the machinery that supports them; either by adopting new approaches (for example, switching from petrol-fuelled to hydrogen-fuelled vehicles), or by increasing the engineering efficiency of existing approaches (for example, using turbo-chargers to increase the efficiency of petrol and diesel engines).
Using more efficient energy generation or exchange technologies – such as re-using the heat from computers to heat offices, or using renewable bio-, wind-, or solar energy sources;
Using new transport technologies for people, resources or goods that changes the economics of the size and frequency of transport; or of the endpoints and routes – such as underground recycling networks;
Replacing transport with other technologies – such as online collaboration;
Reducing wastage and inefficiencies in operation,such as the creation of heat and noise – for example, by switching to lighting technologies such as LED that create less heat.
2. Using information to optimise the operation of city systems
In principle, we can instrument and collect data from any aspect of the systems that support cities; use that data to draw insight into their performance; and use that insight to improve their performance and efficiency in realtime. The ability to do this in practical and affordable ways is relatively new; and offers us the possibility to support larger populations at a higher standard of living whilst using resources more efficiently.
There are challenges, of course. The availability of communication networks to transmit data from where it can be measured to where it can be analysed cannot be assumed. 3G and Wi-Fi coverage is much less complete at ground level, where many city infrastructure components are located, than at head height where humans use mobile phones. And these technologies require expensive, power-hungry transmitters and receivers. New initiatives and startups such as Weightless and SigFox are exploring the creation of communication technologies that promise widespread connectivity at low cost and with low power usage, but they are not yet proven or established.
Despite those challenges, a variety of successful examples exist. Shutl and Carbon Voyage, for example, both use recently emerged technologies to match capacity and demand across networks of transport suppliers; thereby increasing the overall efficiency of the transport systems in the cities where they operate. The Eco-Island Community Interest Company on the Isle of Wight are applying similar concepts to the supply and demand of renwable energy.
Some of the common technologies that enable these solutions at appropriate levels of cost and complexity, are:
Tools for modelling complex systems and providing decision-support.
Asset management and workflow management tools for managing and monitoring the components of city systems and the people who maintain them.
3. Co-ordinating the behaviour of multiple systems to contribute to city-wide outcomes
Many city systems are “silos” that have developed around engineering infrastructures or business and operational models that have evolved since city infrastructures were first laid down. In developed markets, those infrastructures may be more than a century old – London’s underground railway was constructed in the mid 19th Century, for example.
But the “outcomes” sought by cities, neighbourhoods and communities – such as social mobility, economic growth, wellbeing and happiness, safety and sustainability – are usually a consequence of a complex mix of effects of the behaviour of many of those systems – energy, economy, transport, healthcare, retail, education, policing and so on.
As information about the operation and performance of those systems becomes increasingly available; and as our ability to make sense of and exploit that information increases; we can start to analyse, model and predict how the behaviour of city systems affects each other, and how those interactions contribute to the overall outcomes of cities, and of the people and communities in them.
IBM’s recent “Smarter Cities Challenge” in my home city of Birmingham studied detailed maps of the systems in the city and their inputs and outputs, and helped Birmingham City Council understand how to developed those maps into a tool to predict the outcomes of proposed policy changes. In the city of Portland, Oregon, a similar interactive tool has already been produced. And Amsterdam and Dublin have both formed regional partnerships to share and exploit city information and co-ordinate portfolios of projects across city systems and agencies driven by common, city-wide objectives.
We are in the very early stages of developing our ability to quantitatively understand the interrelationships between city systems in this way; but it is already possible to identify some of the technologies that will assist us in that process – in addition to those I mentioned in the previous section:
Cloud computing platforms, which enable data from multiple city systems to be co-located on a single infrastructure; and that can provide the “capacity on demand” to apply analytics and visualisation to that data when required.
Service brokerage capabilities to co-ordinate the behaviour of the IT systems that monitor and control city systems; and the service and data catalogues that make those systems and their information available to those brokers.
Dashboards and other user interface technologies which can present information and services from multiple sources to humans in an understandable and meaningful way.
4. Creating new marketplaces to encourage sustainable choices, and attract investment
The examples in transport innovation that I mentioned earlier in this article, Shutl and Carbon Voyage, can both be thought of as business that exploit information to operate new marketplaces for transport capacity. Eco-island have applied the same concept in energy; Streetline in car-parking; and Big Barn and Sustaination in business-to-consumer and business-to-business models for food distribution.
In addition to those I’ve previously described, systems that operate as transactional marketplaces often involve the following technologies:
The articles I write on this blog cover many aspects of technology, future cities, and urbanism. In several recent articles, including this one, I have focussed in particular on issues concerning the application of technology to city systems.
I believe these issues are important. It is inarguable that technology has been changing our world since human beings first used tools; and overall the rate of change has been accelerating ever since. That acceleration has been particularly rapid in the past few decades. The fact that this blog, which costs me nothing to write other than my own time, has been read by people from 117 countries this year – including you – is just one very mundane example of something that would have been completely unthinkable when I started my University education.
But I absolutely do not want to give the impression that technology is the most important element of the future of cities; or that every “Smarter City” project requires all – or even any – of the technologies that I’ve described in this article.
Smarter Cities start with conversations between people; conversations build trust and understanding, and lead to the creation of new ideas. Many of those ideas are first shaped on pen and paper – often still the least invasive technology for co-creating and recording information that we have. Some of those ideas will be realised through the application of more recent technologies – and in fact will only be possible at all because of them. That is the real value that new technology brings to the future of cities.
But it’s important to get the order right, or we will not achieve the outcomes that we need. Conversations, paper, technology – that might just be the real roadmap for Smarter Cities.
(Recycling bins in Curitiba, Brazil photographed by Ana Elisa Ribeiro)
In the past few years, terms such as “Smart Cities” and “Future Cities” have emerged to capture the widespread sense that the current decade is one in which trends in technology, the economy, demographics and the environment are coinciding in an exciting and meaningful way.
Common patterns have emerged in the technology platforms that enable us to address these economic, social and environmental challenges. For example, the “Digital Cities Exchange” research programme at Imperial College, London; the “FI-WARE” project researching the core platform for the “future internet”; the “European Platform for Intelligent Cities (EPIC)“; and IBM’s own “Intelligent Operations Centre” all share a similar architecture.
I think of these platforms as 21st Century “civic infrastructures”. They will provide services that can be composed into new city systems and local marketplaces. Those services will include the management of personal data and identity; authentication; local currencies; micro-payments; and the ability to access data about city systems, amongst others.
Cities are such complex systems of systems, and face such a multitude of challenges in a rich variety of contexts, that no single technology solution could possibly address them all. In fact an incredibly rich variety of technologies has already been used to create “Smart” systems in cities. But whilst I’m preparing an article that I hope to publish on this blog next week that lays out a framework for considering those technologies systematically, there’s a more fundamental observation that’s worth making:
Some of the technologies at the heart of urban innovations are incredibly simple.
15 years ago, I lived through the transformation of a city neighbourhood that illustrates this point. It involved community activism and crowdsourced information, enabled by an accessible technology – analogue photography.
As a University student in Birmingham, I lived in rented accommodation in the city’s Balsall Heath area. Balsall Heath has one of Birmingham’s largest Muslim communities, in addition to its substantial student population.
And, for the best part of half a century from the 1950s to the 1990s, it was Birmingham’s “red light” district, the centre of prostitution in the city.
Balsall Heath was clearly a district with substantial differences in culture – which were accommodated very peacefully, I should say. But in 1994, members of the Muslim community decided to change their neighbourhood. They put out old sofas and chairs on street corners, and sat on them each night, photographing anyone walking or driving around the area seeking prostitutes. Those simple steps tapped into the social motivations of those people and had a powerfully discouraging effect on them. Over the course of a year, prostitution was driven out of Balsall Heath for the first time in 50 years. It has never returned, and the district and its communities were strengthened as a result. The UK Prime Minister David Cameron has referred to the achievements of Balsall Heath’s community as an inspiration for his “Big Society” initiative.
I have just given a very simplified description of a complex set of events and issues; and in particular, I did not include the perspective of the working women who were perhaps the most vulnerable people involved. But this example of a simple technology (analogue photography) applied by a community to improve their district, with an understanding of the personal and social motivations that affect individual behaviour and choice, is an example that I have been regularly reminded of throughout my work in social media and Smarter Cities.
(Photo from Digital Balsall Heath of residents warning kerb-crawlers on Cheddar Road in the 1990s that they would be watched and recorded)
The city systems facing economic, demographic and environmental challenges today are immensely complex. They provide life-support for city populations – feeding, transporting, and educating them; providing healthcare; and supporting individuals, communities and businesses. As we continue to optimise their operation to support larger, more dense urban populations, maintaining their resilience is a significant challenge.
At the same time, though, the simplicity of Balsall Heath’s community action in the 1990s is inspirational; and there are many other examples.
These innovations will not always be simply transferable from one city to another; but they could form the basis of a catalogue or toolkit of re-usable ideas, as was suggested by the Collective Research Initiatives Trust (CRIT) in their research on urban innovation in Mumbai, “Being Nicely Messy“, echoing Colin Rowe and Fred Koetter’s “Collage City“.
As I wrote recently in the article “Zen and the art of messy urbanism“, many of the Smart systems of tomorrow will be surprising innovations that cut across and disrupt the industry sectors and classifications of city systems that we understand today; and in order to provide food, energy, water, transport and other services to city populations, they will need to be robustly engineered. But drawing inspiration from good, simple ideas with their roots in human behaviour rather than new technology is surely a good starting point from which to begin our journey towards discovering them.
(Millenium Point, home of Birmingham’s Science Museum and Birmingham City University’s Technology Innovation Centre, photographed by Martin Hartland)
Back in September, we held the last meeting of the Birmingham Science City Digital Working Group – my first meeting as chair. We were joined by many enthusiastic representatives of Birmingham and the region’s digital community – entrepreneurs, small businesses, industry interest groups, universities and companies.
We had a thought provoking discussion of how the Digital Working Group can continue to be a valued forum and a catalyst for its members to share insight, create new ideas, and discover new opportunities in the digital economy; contributing to and benefitting from the Birmingham Science City objectives to create “scientific, technological and economic advantage for wealth, opportunity and worth”. In such a challenging economy, with funding for innovation and enterprise in short supply, such exchanges can stimulate new activity by increasing awareness of the resources that are nevertheless available.
The consensus we seemed to reach was that the working group could do that by:
Bringing together stakeholders from our digital community who are aware of problems and challenges, and those who may be aware of solutions;
Focussing on emerging opportunities for technology to contribute to Birmingham Science City’s economic and social objectives, but for which the business models are not yet clear;
Using social media between meetings to explore specific topics within those broad criteria so that each face-to-face meeting has a clear agreed agenda beforehand;
And continuing to use the group to provide updates between members, and in particular an update on current opportunities to access funds and resources.
“New patterns of work emerged as the new entrepreneurs struggled to survive and settle. they occupied varied locations and blurred the distinction between formality and informality …
… the entrepreneurs of Mumbai have innovatively occupied city spaces maximizing their efficiency …
… the blurry / messy condition further contributes to the high transactional capacity of the urban form.”
These remarks emphasise to me the need for us to be very open in considering where innovation and opportunity might emerge from; and what form it might take. The markets, business models and technologies we know today are in many cases unrecognisable from the world of only a few years ago; we should expect any and all of our assumptions to be challenged by the innovations that emerge in the very near future.
With these thoughts and provocations in mind, I’m thinking of organising the agenda of our next meeting, which will be in early December, around the following topics:
Introduction and review of the last meeting
Update on innovation investment and support
An update on current trends in funding – e.g. from a local venture capitalist, or an update on tax credits for Research and Development from a Digital Working Group member
An update on funding and projects from Birmingham Science City
Introduction to the theme for the meeting
Provocation
An alternative viewpoint from Birmingham Science City – i.e. from somebody outside the usual Digital Working Group Community; and perhaps in this case from the Low Carbon Working Group, as discussed at our last meeting
Creative discussion:
How can Birmingham’s digital community exploit this theme, and how can the Digital Working Group help?
Next steps, and discussion of the agenda for the next meeting
(Matthew Boulton, James Watt and William Murdoch, Birmingham’s three fathers of the Industrial Revolution, photographed by Neil Howard)
So what should our “theme” be?
In our last meeting we agreed that the area of Low Carbon technology was an interesting one for us to explore; and there are already interesting initiatives underway in that area in Birmingham, such as the “Birmingham Energy Savers” project, and the European Bio-Energy Research Institute, who are seeking to establish a regional supply chain of SMEs to support their work to develop small-scale, sustainable technology for recovering energy from waste food and sewage.
So my suggested theme is:
“How can the Birmingham Science City Digital Working Group create or stimulate innovation using digital technology to contribute to a low carbon economy – whether in the transport and energy sectors or elsewhere?”
If the Digital Working Group is able to do that, it could help Birmingham’s economy access the investment resources available to support low carbon innovation; potentially assisting in the creation of jobs, as well as lowering the city’s carbon footprint and improving its physical environment.
This discussion, in fact, reminds me of some important statements in Birmingham Science City’s Constitution; the constitution states that Birmingham Science City should stimulate collaborative innovation in using science and technology to create wealth, opportunity and worth by:
“Developing activities that increase public appreciation of the application of Science & Technology and the economic, employment and quality of life benefits that it can bring.”
and:
“Encouraging collective maintenance and development of resources for innovation including finance and physical infrastructure.”
I’d like this suggestion to be the start of a discussion; hence I’m making it in this public forum, and posting links to it in several discussion groups on Linked-In as well as sending it to the Digital Working Group members by e-mail.
I look forward to hearing from the Digital Working Group members – or any other interested parties – for comments and feedback to my proposal for the next meeting.
(Graphic of New York’s ethnic diversity from Eric Fischer)
I often use this blog to explore ways in which technology can add value to city systems. In this article, I’m going to dig more deeply into my own professional expertise: the engineering of the platforms that make technology reliably available.
Many cities are considering how they can create a city-wide information platform. The potential benefits are considerable: Dublin’s “Dublinked” platform, for example, has stimulated the creation of new high-technology businesses, and is used by scientific researchers to examine ways in which the city’s systems can operate more efficiently and sustainably. And the announcements today by San Francisco that they are legislating to promote open data and have appointed a “Chief Data Officer” for the city are sure to add to the momentum.
But if cities such as Dublin, San Francisco and Chicago have found such platforms so useful, why aren’t there more of them already?
To answer that question, I’d like to start by setting an expectation:
City information platforms are not “new” systems; they are a brownfield regeneration challenge for technology.
Just as urban regenerations need to take account of the existing physical infrastructures such as buildings, transport and utility networks; when thinking about new city technology solutions we need to consider the information infrastructure that is already in place.
A typical city authority has many hundreds of IT systems and applications that store and manage data about their city and region. Private sector organisations who operate services such as buses, trains and power, or who simply own and operate buildings, have similarly large and complex portfolios of applications and data.
So in every city there are thousands – probably tens of thousands – of applications and data sources containing relevant information. (The Dublinked platform was launched in October 2011 with over 3,000 data sets covering the environment, planning, water and transport, for example). Only a very small fraction of those systems will have been designed with the purpose of making information available to and usable by city stakeholders; and they certainly will not have been designed to do so in a joined-up, consistent way.
(A map of the IT systems of a typical organisation, and the interconnections between then)
The picture to the left is a reproduction of a map of the IT systems of a real organisation, and the connections between them. Each block in the diagram represents a major business application that manages data; each line represents a connection between two or more such systems. Some of these individual systems will have involved hundreds of person-years of development over decades of time. Engineering the connections between them will also have involved significant effort and expense.
Whilst most organisations improve the management of their systems over time and sometimes achieve significant simplifications, by and large this picture is typical of the vast majority of organisations today, including those that support the operation of cities.
In the rest of this article, I’ll explore some of the specific challenges for city data and open data that result from this complexity.
My intention is not to argue against bringing city information together and making it available to communities, businesses and researchers. As I’ve frequently argued on this blog, I believe that doing so is a fundamental enabler to transforming the way that cities work to meet the very real social, economic and environmental challenges facing us. But unless we take a realistic, informed approach and undertake the required engineering diligence, we will not be successful in that endeavour.
1. Which data is useful?
Amongst those thousands of data sets that contain information about cities, on which should we concentrate the effort required to make them widely available and usable?
That’s a very hard question to answer. We are seeking innovative change in city systems, which by definition is unpredictable.
One answer is to look at what’s worked elsewhere. For example, wherever information about transport has been made open, applications have sprung up to make that information available to travellers and other transport users in useful ways. In fact most information that describes the urban environment is likely to quickly prove useful; including maps, land use characterisation, planning applications, and the locations of shops, parks, public toilets and other facilities .
The other datasets that will prove useful are less predictable; but there’s a very simple way to discover them: ask. Ask local entrepreneurs what information they need to start new businesses. Ask existing businesses what information about the city would help them be more successful. Ask citizens and communities.
This is the approach we have followed in Sunderland, and more recently in Birmingham through the Smart City Commission and the recent “Smart Hack” weekend. The Dublinked information partnership in Dublin also engages in consultation with city communities and stakeholders to prioritise the datasets that are made available through the platform. The Knight Foundation’s “Information Needs of Communities” report is an excellent explanation of the importance of taking this approach.
2. What data is available?
How do we know what information is contained in those hundreds or thousands of data sets? Many individual organisations find it difficult to “know what they know”; across an entire city the challenge is much harder.
Arguably, that challenge is greatest for local authorities: whilst every organisation is different, as a rule of thumb private sector companies tend to need tens to low hundreds of business systems to manage their customers, suppliers, products, services and operations. Local authorities, obliged by law to deliver hundreds or even thousands of individual services, usually operate systems numbering in the high hundreds or low thousands. The process of discovering, cataloguing and characterising information systems is time-consuming and hence potentially expensive.
The key to resolving the dilemma is an open catalogue which allows this information to be crowdsourced. Anyone who knows of or discovers a data source that is available, or that could be made available, and whose existence and contents are not sensitive, can document it. Correspondingly, anyone who has a need for data that they cannot find or use can document that too. Over time, a picture of the information that describes a city, including what data is available and what is not, will build up. It will not be a complete picture – certainly not initially; but this is a practically achievable way to create useful information.
3. What is the data about?
The content of most data stores is organised by a “key” – a code that indicates the subject of each element of data. That “key” might be a person, a location or an organisation. Unfortunately, all of those things are very difficult to identify correctly and in a way that will be universally understood.
For example, do the following pieces of information refer to the same people, places and organisations?
“Mr. John Jones, Davis and Smith Delicatessen, Harbourne, Birmingham” “J A Jones, Davies and Smythe, Harborne, B17” “The Manager, David and Smith Caterers, Birmingham B17” “Mr. John A and Mrs Jane Elizabeth Jones, 14 Woodhill Crescent, Northfield, Birmingham”
This information is typical of what might be stored in a set of IT systems managing such city information as business rates, citizen information, and supplier details. As human beings we can guess that a Mr. John A Jones lives in Northfield with his wife Mrs. Jane Elizabeth Jones; and that he is the manager of a delicatessen called “Davis and Smith” in Harborne which offers catering services. But to derive that information we have had to interpret several different ways of writing the names of people and businesses; tolerate mistakes in spelling; and tolerate different semantic interpretations of the same entity (is “Davis and Smith” a “Delicatessen” or a “Caterer”? The answer depends on who is asking the question).
(Two views of Exhibition Road in London, which can be freely used by pedestrians, for driving and for parking; the top photograph is by Dave Patten. How should this area be classified? As a road, a car park, a bus-stop, a pavement, a park – or something else? My colleague Gary looks confused by the question in the bottom photograph!)
All of these challenges occur throughout the information stored in IT systems. Some technologies – such as “single view” – exist that are very good at matching the different formats of names, locations and other common pieces of information. In other cases, information that is stored in “codes” – such as “LHR” for “London Heathrow” and “BHX” for “Birmingham International Airport” can be decoded using a glossary or reference data.
Translating semantic meanings is more difficult. For example, is the A45 from Birmingham to Coventry a road that is useful for travelling between the two cities? Or a barrier that makes it difficult to walk from homes on one side of the road to shops on the other? In time semantic models of cities will develop to systematically reconcile such questions, but until they do, human intelligence and interpretation will be required.
4. Sometimes you don’t want to know what the data is about
Sometimes, as soon as you know what something is about, you need to forget that you know. I led a project last year that applied analytic technology to derive new insights from healthcare data. Such data is most useful when information from a variety of sources that relate to the same patient is aggregated together; to do that, the sort of matching I’ve just described is needed. But patient data is sensitive, of course; and in such scenarios patients’ identities should not be apparent to those using the data.
Techniques such as anonymisation and aggregation can be applied to address this requirement; but they need to be applied carefully in order to retain the value of data whilst ensuring that identities and other sensitive information are not inadvertently exposed.
For example, the following information contains an anonymised name and very little address information; but should still be enough for you to determine the identity of the subject:
Subject: 00764 Name: XY67 HHJK6UB Address: SW1A Profession: Leader of a political party
(Please submit your answers to me at @dr_rick on Twitter!)
This is a contrived example, but the risk is very real. I live on a road with about 100 houses. I know of one profession to which only two people who live on the road belong. One is a man and one is a woman. It would be very easy for me to identify them based on data which is “anonymised” naively. These issues become very, very serious when you consider that within the datasets we are considering there will be information that can reveal the home address of people who are now living separately from previously abusive partners, for example.
5. Data can be difficult to use
(How the OECD identified the “Top 250 ICT companies” in 2006)
There are many, many reasons why data can be difficult to use. Data contained within a table within a formatted report document is not much use to a programmer. A description of the location of a disabled toilet in a shop can only be used by someone who understands the language it is written in. Even clearly presented numerical values may be associated with complex caveats and conditions or expressed in quantities specific to particular domains of expertise.
For example, the following quote from a 2006 report on the global technology industry is only partly explained by the text box shown in the image on the left:
“In 2005, the top 250 ICT firms had total revenues of USD 3 000 billion”.
Technology can address some of these issues: it can extract information from written reports; transform information between formats; create structured information from written text; and even, to a degree, perform automatic translation between languages. But doing all of that requires effort; and in some cases human expertise will always be required.
In order for city information platforms to be truly useful to city communities, then some thought also needs to be given for how those communities will be offered support to understand and use that information.
Such deliberate manipulation is just one of the many reasons we may have to doubt information. Who creates information? How qualified are they to provide accurate information? Who assesses that qualification and tests the accuracy of the information?
For example, every sensor which measures physical information incorporates some element of uncertainty and error. Location information derived from Smartphones is usually accurate to within a few meters when derived from GPS data; but only a few hundred meters when derived by triangulation between mobile transmission masts. That level of inaccuracy is tolerable if you want to know which city you are in; but not if you need to know where the nearest cashpoint is. (Taken to its extreme, this argument has its roots in “Noise Theory“, the behaviour of stochastic processes and ultimately Heisenberg’s Uncertainty Principle in Quantum Mechanics. Sometimes it’s useful to be a Physicist!).
Information also goes out of date very quickly. If roadworks are started at a busy intersection, how does that affect the route-calculation services that many of us depend on to identify the quickest way to get from one place to another? When such roadworks make bus stops inaccessible so that temporary stops are erected in their place, how is that information captured? In fact, this information is often not captured; and as a result, many city transport authorities do not know where all of their bus stops are currently located.
I have barely touched in this section on an enormously rich and complex subject. Suffice to say that determining the “trustability” of information in the broadest sense is an immense challenge.
7. Data is easy to lose
(A computer information failure in Las Vegas photographed by Dave Herholz)
Whenever you find that an office, hotel room, hospital appointment or seat on a train that you’ve reserved is double-booked you’ve experienced lost data. Someone made a reservation for you in a computer system; that data was lost; and so the same reservation was made available to someone else.
Some of the world’s most sophisticated and well-managed information systems lose data on occasion. That’s why we’re all familiar with it happening to us.
If cities are to offer information platforms that local people, communities and businesses come to depend on, then we need to accept that providing reliable information comes at a cost. This is one of the many reasons that I have argued in the past that “open data” is not the same thing as “free data”. If we want to build a profitable business model that relies on the availability of data, then we should expect to pay for the reliable supply of that data.
A Brownfield Regeneration for the Information Age
So if this is all so hard, should we simply give up?
Of course not; I don’t think so, anyway. In this article, I have described some very significant challenges that affect our ability to make city information openly available to those who may be able to use it. But we do not need to overcome all of those challenges at once.
That last part is crucial. The financial value that results from such “Smarter City” innovations might not be our primary objective in this context – we are more likely to be concerned with economic, social and environmental outcomes; but it is precisely what is needed to support the financial investment required to overcome the challenges I have discussed in this article.
On a final note, it is obviously the case that I am employed by a company, IBM, which provides products and services that address those challenges. I hope that you have noticed that I have not mentioned a single one of those products or services by name in this article, nor provided any links to them. And whilst IBM are involved in some of the cities that I have mentioned, we are not involved in all of them.
I have written this article as a stakeholder in our cities – I live in one – and as an engineer; not as a salesman. I am absolutely convinced that making city information more widely available and usable is crucial to addressing what Professor Geoffrey West described as “the greatest challenges that the planet has faced since humans became social“. As a professional engineer of information systems I believe that we must be fully cognisant of the work involved in doing so properly; and as a practical optimist, I believe that it is possible to do so in affordable, manageable steps that create real value and the opportunity to change our cities for the better. I hope that I have managed to persuade you to agree.
I’m the Director of Smart Places for Jacobs, the global engineering company. Previously, I was the UK, Middle East and Africa leader of the Digital Cities and Property business for Arup, Director of Technology for Amey, one of the UK’s largest engineering and infrastructure services companies and part of the international Ferrovial Group, and before that IBM UK’s Executive Architect for Smarter Cities.
You can connect to me on Twitter as @dr_rick; or contact me through Linked-In where I’ll respond to connection requests from people I know, or that are accompanied by a message that starts a meaningful discussion.
The opinions on this site are my own.
Creative Commons
Content on this blog can be shared under the terms of the Creative Commons Attribution-ShareAlike License: you are free to share and re-use it providing you attribute this blog as the source of the material, and license any resulting work on similar terms. Please refer to the full license terms, or contact me with any requests to re-use material on a different basis.