Can Smarter City technology measure and improve our quality of life?
September 24, 2013 11 Comments

(Photo of Golden Gate Bridge, San Francisco, at night by David Yu)
Can information and technology measure and improve the quality of life in cities?
That seems a pretty fundamental question for the Smarter Cities movement to address. There is little point in us expending time and money on the application of technology to city systems unless we can answer it positively. It’s a question that I had the opportunity to explore with technologists and urbanists from around the world last week at the Urban Systems Collaborative meeting in London, on whose blog this article will also appear.
Before thinking about how we might approach such a challenging and complex issue, I’d like to use two examples to support my belief that we will eventually conclude that “yes, information and technology can improve the quality of life in cities.”
The first example, which came to my attention through Colin Harrison, who heads up the Urban Systems Collaborative, concerns public defibrillator devices – equipment that can be used to give an electric shock to the victim of a heart attack to restart their heart. Defibrillators are positioned in many public buildings and spaces. But who knows where they are and how to use them in the event that someone nearby suffers a heart attack?
To answer those questions, many cities now publish open data lists of the locations of publically-accessible Defibrillators. Consequently, SmartPhone apps now exist that can tell you where the nearest one to you is located. As cities begin to integrate these technologies with databases of qualified first-aiders and formal emergency response systems, it becomes more feasible that when someone suffers a heart attack in a public place, a nearby first-aider might be notified of the incidence and of the location of a nearby defibrillator, and be able to respond valuable minutes before the arrival of emergency services. So in this case, information and technology can increase the chancees of heart attack victims recovering.
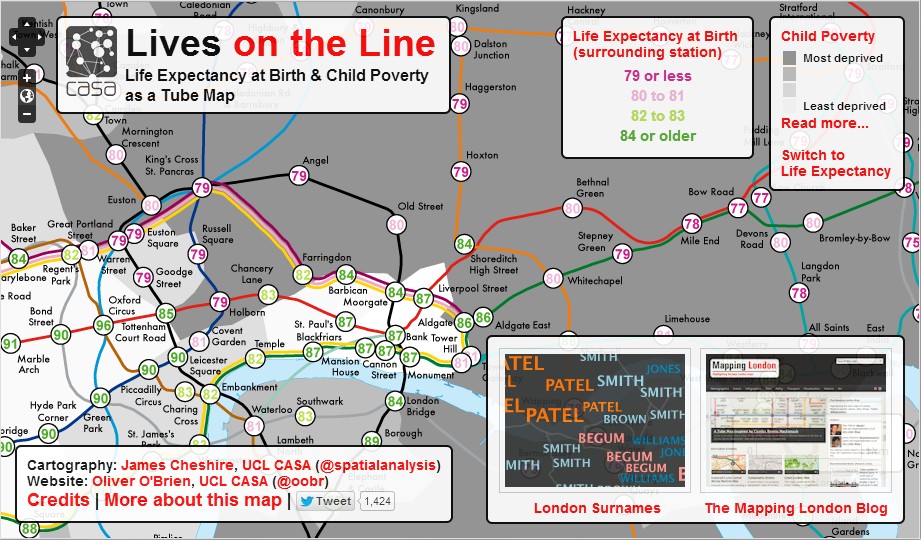
(Why Smarter Cities matter: “Lives on the Line” by James Cheshire at UCL’s Centre for Advanced Spatial Analysis, showing the variation in life expectancy across London. From Cheshire, J. 2012. Lives on the Line: Mapping Life Expectancy Along the London Tube Network. Environment and Planning A. 44 (7). Doi: 10.1068/a45341)
In a more strategic scenario, the Centre for Advanced Spatial Analysis (CASA) at University College London have mapped life expectancy at birth across London. Life expectancy across the city varies from 75 to 96 years, and CASA’s researchers were able to correlate it with a variety of other issues such as child poverty.
Life expectancy varies by 10 or 20 years in many cities in the developed world; analysing its relationship to other economic, demographic, social and spatial information can provide insight into where money should be spent on providing services that address the issues leading to it, and that determine quality of life. The UK Technology Strategy Board cited Glasgow’s focus on this challenge as one of their reasons for investing £24 million in Glasgow’s Future Cities Demonstrator project – life expectancy at birth for male babies in Glasgow varies by 26 years between the poorest and wealthiest areas of the city.
These examples clearly show that in principle urban data and technology can contribute to improving quality of life in cities; but they don’t explain how to do so systematically across the very many aspects of quality of life and city systems, and between the great variety of urban environments and cultures throughout the world. How could we begin to do that?
Deconstructing “quality of life”
We must first think more clearly about what we mean by “quality of life”. There are many needs, values and outcomes that contribute to quality of life and its perception. Maslow’s “Hierarchy of Needs” is a well-researched framework for considering them. We can use this as a tool for considering whether urban data can inform us about, and help us to change, the ability of a city to create quality of life for its inhabitants.

(Maslow’s Hierarchy of Needs, image by Factoryjoe via Wikimedia Commons)
But whilst Maslow’s hierarchy tells us about the various aspects that comprise the overall quality of life, it only tells us about our relationship with them in a very general sense. Our perception of quality of life, and what creates it for us, is highly variable and depends on (at least) some of the following factors:
- Individual lifestyle preferences
- Age
- Culture and ethnicity
- Social standing
- Family status
- Sexuality
- Gender
- … and so on.
Any analysis of the relationship between quality of life, urban data and technology must take this variability into account; either by allowing for it in the analytic approach; or by enabling individuals and communities to customise the use of data to their specific needs and context.
Stress and Adaptability
Two qualities of urban systems and life within them that can help us to understand how urban data of different forms might relate to Maslow’s hierarchy of needs and individual perspectives on it are stress and adaptability.
Jurij Paraszczak, IBM’s Director of Research for Smarter Cities, suggested that one way to improve quality of life is to reduce stress. A city with efficient, well integrated services – such as transport; availability of business permits etc. – will likely cause less stress, and offer a higher quality of life, than a city whose services are disjointed and inefficient.
One cause of stress is the need to change. The Physicist Geoffrey West is one of many scientists who has explored the roles of technology and population growth in speeding up city systems; as our world changes more and more quickly, our cities will need to become more agile and adaptable – technologists, town planners and economists all seem to agree on this point.
The architect Kelvin Campbell has explored how urban environments can support adaptability by enabling actors within them to innovate with the resources available to them (streets, buildings, spaces, technology) in response to changes in local and global context – changes in the economy of cultural trends, for example.
“Service scientists” analyse the adaptability of systems (such as cities) by considering the “affordances” they offer to actors within them. An “affordance” is a capability within a system that is not exercised until an actor chooses to exercise it in order to create value that is specific to them, and specific to the time, place and context within which they act.
An “affordance” might be the ability to start a temporary business or “pop-up” shop within a disused building by exploiting a temporary exemption from planning controls. Or it might be the ability to access open city data and use it as the basis of new information-based business services. (I explored some ideas from science, technology, economics and urbanism for creating adaptability in cities in an article in March this year).

(Photo by lecercle of a girl in Mumbai doing her homework on whatever flat surface she could find. Her use of a stationary tool usually employed for physical mobility to enhance her own social mobility is an example of the very basic capacity we all have to use the resources available to us in innovative ways)
Stress and adaptability are linked. The more personal effort that city residents must exert in order to adapt to changing circumstances (i.e. the less that a city offers them useful affordances), then the more stress they will be subjected to.
Stress; rates of change; levels of effort and cost exerted on various activities: these are all things that can be measured.
Urban data and quality of life in the district high street
In order to explore these ideas in more depth, our discussion at the Urban Systems Collaborative meeting explored a specific scenario systematically. We considered a number of candidate scenarios – from a vast city such as New York, with a vibrant economy but affected by issues such as flood risk; through urban parks and property developments down to the scale of an individual building such as a school or hospital.
We chose to start with a scenario in the middle of that scale range that is the subject of particularly intense debate in economics, policy and urban design: a mixed-demographic city district with a retail centre at its heart spatially, socially and economically.
We imagined a district with a population of around 50,000 to 100,000 people within a larger urban area; with an economy including the retail, service and manufacturing sectors. The retail centre is surviving with some new businesses starting; but also with some vacant property; and with a mixture of national chains, independent specialist stores, pawnshops, cafes, payday lenders, pubs and betting shops. We imagined that local housing stock would support many levels of wealth from benefits-dependent individuals and families through to millionaire business owners. A district similar to Kings Heath in Birmingham, where I live, and whose retail economy was recently the subject of an article in the Economist magazine.
We asked ourselves what data might be available in such an environment; and how it might offer insight into the elements of Maslow’s hierarchy.
We began by considering the first level of Maslow’s hierarchy, our physiological needs; and in particular the availability of food. Clearly, food is a basic survival need; but the availability of food of different types – and our individual and cultural propensity to consume them – also contributes to wider issues of health and wellbeing.

(York Road, Kings Heath, in the 2009 Kings Heath Festival. Photo by Nick Lockey)
Information about food provision, consumption and processing can also give insights into economic and social issues. For example, the Economist reported in 2011 that since the 2008 financial crash, some jobs lost in professional service industries such as finance in the UK had been replaced by jobs created in independent artisan industries such as food. Evidence of growth in independent businesses in artisan and craft-related sectors in a city area may therefore indicate the early stages of its recovery from economic shock.
Similarly, when a significant wave of immigration from a new cultural or ethnic group takes place in an area, then it tends to result in the creation of new, independent food businesses catering to preferences that aren’t met by existing providers. So a measure of diversity in food supply can be an indicator of economic and social growth.
So by considering a need that Maslow’s hierarchy places at the most basic level, we were able to identify data that describes an urban area’s ability to support that need – for example, the “Enjoy Kings Heath” website provides information about local food businesses; and furthermore, we identified ways that the same data related to needs throughout the other levels of Maslow’s hierarchy.
We next considered how economic flows within and outside an area can indicate not just local levels of economic activity; but also the area’s trading surplus or deficit. Relevant information in principle exists in the form of the accounts and business reports of businesses. Initiatives such as local currencies and loyalty schemes attempt to maximise local synergies by minimising the flow of money out of local economies; and where they exploit technology platforms such as Droplet’s SmartPhone payments service, which operates in London and Birmingham, the money flows within local economies can be measured.
These money flows have effects that go beyond the simple value of assets and property within an area. Peckham high street in London has unusually high levels of money flow in and out of its economy due to a high degree of import / export businesses; and to local residents transferring money to relatives overseas. This flow of money makes business rents in the area disproportionally high compared to the value of local assets.
Our debate also touched on environmental quality and transport. Data about environmental quality is increasingly available from sensors that measure water and air quality and the performance of sewage systems. These clearly contribute insights that are relevant to public health. Transport data provides perhaps more subtle insights. It can provide insight into economic activity; productivity (traffic jams waste time); environmental impact; and social mobility.
My colleagues in IBM Research have recently used anonymised data from GPS sensors in SmartPhones to analyse movement patterns in cities such as Abidjan and Istanbul on behalf of their governments and transport authorities; and to compare those movement patterns with public transport services such as bus routes. When such data is used to alter public transport services so that they better match the end-to-end journey requirements of citizens, an enormous range of individual, social, environmental and economic benefits are realised.
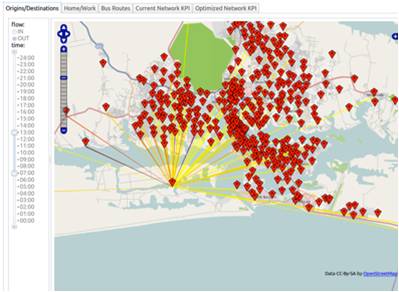
(The origins and destinations of end-to-end journeys made in Abidjan, identified from anonymised SmartPhone GPS data)
Finally, we considered data sources and aspects of quality of life relating to what Maslow called “self-actualisation”: the ability of people within the urban environment of our scenario to create lifestyles and careers that are individually fulfilling and that reward creative self-expression. Whilst not direct, measurements of the registration of patents, or of the formation and survival of businesses in sectors such as construction, technology, arts and artisan crafts, relate to those values in some way.
In summary, the exercise showed that a great variety of data is available that relates to the ability of an urban environment to provide Maslow’s hierarchy of needs to people within it. To gain a fuller picture, of course, we would need to repeat the exercise with many other urban contexts at every scale from a single building up to the national, international and geographic context within which the city exists. But this seems a positive start.
Of course, it is far from straightforward to convert these basic ideas and observations into usable techniques for deriving insight and value concerning quality of life from urban data.
What about the things that are extremely hard to measure but which are often vital to quality of life – for example the cash economy? Physical cash is notoriously hard to trace and monitor; and arguably it is particularly important to the lives of many individuals and communities who have the most significant quality of life challenges; and to those who are responsible for some of the activities that detract from quality of life – burglary, mugging and the supply of narcotics, for example.
The Urban Systems Collaborative’s debate also touched briefly on the question of whether we can more directly measure the outcomes that people care about – happiness, prosperity, the ability to provide for our families, for example. Antti Poikola has written an article on his blog, “Vital signs for measuring the quality of life in cities“, based on the presentation on that topic by Samir Menon of Tata Consulting Services. Samir identified a number of “happiness indices” that have been proposed by the UK Prime Minister, David Cameron, the European Quality of Life Survey, the OECD’s Better Life Index, and the Social Progress Index created by economist Michael Porter. Those indices generally attempt to correlate a number of different quantitative indicators with qualitative information from surveys into an overall score. Their accuracy and usefulness is the subject of contentious debate.
As an alternative, Michael Mezey of the Royal Society for the Arts recently collected descriptions of attempts to measure happiness more directly by identifying the location of issues or events associated with positive or negative emotions – such as parks and pavements fouled by dog litter or displays of emotion in public. It’s fair to say that the results of these approaches are very subjective and selective so far, but it will be interesting to observe what progress is made.
There is also a need to balance our efforts between creating value from the data that is available to us – which is surely a resource that we should exploit – with making sure that we focus our efforts on addressing our most important challenges, whether or not data relevant to them is easily accessible.
And in practise, a great deal of the data that describes cities is still not very accessible or useful. Most of it exists within IT systems that were designed for a specific purpose – for example, to allow building owners to manage the maintenance of their property. Those systems may not be very good at providing data in a way that is useful for new purposes – for example, identifying whether a door is connected to a pavement by a ramp or by steps, and hence how easy it is for a wheelchair user to enter a building.

(Photo by Closed 24/7 of the Jaguar XF whose designers used “big data” analytics to optimise the emotional response of potential customers and drivers)
Generally speaking, transforming data that is useful for a specific purpose into data that is generally useful takes time, effort and expertise – and costs money. We may desire city data to be tidied up and made more readily accessible; just as we may desire a disused factory to be converted into useful premises for shops and small businesses. But securing the investment required to do so is often difficult – this is why open city data is a “brownfield regeneration” challenge for the information age.
We don’t yet have a general model for addressing that challenge, because the socio-economic model for urban data has not been defined. Who owns it? What does it cost to create? What uses of it are acceptable? When is it proper to profit from data?
Whilst in principle the data available to us, and our ability to derive insight and knowledge from it, will continue to grow, our ability to benefit from it in practise will be determined by these crucial ethical, legal and economic issues.
There are also more technical challenges. As any mathematician or scientist in a numerate discipline knows, data, information and analysis models have significant limitations.
Any measurement has an inherent uncertainty. Location information derived from Smartphones is usually accurate to within a few meters when GPS services are available, for example; but only to within a few hundred meters when derived by triangulation between mobile transmission masts. That level of inaccuracy is tolerable if you want to know which city you are in; but not if you need to know where the nearest defibrilator is.
These limitations arise both from the practical limitations of measurement technology; and from fundamental scientific principles that determine the performance of measurement techniques.
We live in a “warm” world – roughly 300 degrees Celsius above what scientists call “absolute zero“, the coldest temperature possible. Warmth is created by heat energy; that energy makes the atoms from which we and our world are made “jiggle about” – to move randomly. When we touch a hot object and feel pain it is because this movement is too violent to bear – it’s like being pricked by billions of tiny pins. This random movement creates “noise” in every physical system, like the static we hear in analogue radio stations or on poor quality telephone lines.
And if we attempt to measure the movements of the individual atoms that make up that noise, we enter the strange world of quantum mechanics in which Heisenberg’s Uncertainty Principle states that the act of measuring such small objects changes them in unpredictable ways. It’s hardly a precise analogy, but imagine trying to measure how hard the surface of a jelly is by hitting it with a hammer. You’d get an idea of the jelly’s hardness by doing so, but after the act of “measurement” you wouldn’t be left with the same jelly. And before the measurement you wouldn’t be able to predict the shape of the jelly afterwards.

(A graph from my PhD thesis showing experimental data plotted against the predictions of an analytic. Notice that whilst the theoretical prediction (the smooth line) is a good guide to the experimental data, that each actual data point lies above or below the line, not on it. In addition, each data point has a vertical bar expressing the level of uncertainty involved in its measurement. In most circumstances, data is uncertain and theory is only a rough guide to reality.)
Even if our measurements were perfect, our ability to understand what they are telling us is not. We draw insight into the behaviour of a real system by comparing measurements of it to a theoretical model of its behaviour. Weather forecasters predict the weather by comparing real data about temperature, air pressure, humidity and rainfall to sophisticated models of weather systems; but, as the famous British preoccupation with talking about the weather illustrates, their predictions are frequently inaccurate. Quite simply this is because the weather system of our world is more complicated than the models that weather forecasters are able to describe using mathematics; and process using today’s computers.
This may all seem very academic; and indeed it is – these are subjects that I studied for my PhD in Physics. But all scientists, mathematicians and engineers understand them; and whether our work involves city systems, motor cars, televisions, information technology, medicine or human behaviour, when we work with data, information and analysis technology we are very much aware and respectful of their limitations.
Most real systems are more complicated than the theoretical models that we are able to construct and analyse. That is especially true of any system that includes the behaviour of people – in other words, the vast majority of city systems. Despite the best efforts of psychology, social science and artificial intelligence we still do not have an analytic model of human behaviour.
For open data and Smarter Cities to succeed, we need to openly recognise these challenges. Data and technology can add immense value to city systems – for instance, IBM’s “Deep Thunder” technology creates impressively accurate short-term and short-range predictions of weather-related events such as flash-flooding that have the potential to save lives. But those predictions, and any other result of data-based analysis, have limitations; and are associated with caveats and constraints.
It is only by considering the capabilities and limitations of such techniques together that we can make good decisions about how to use them – for example, whether to trust our lives to the automated analytics and control systems involved in anti-lock braking systems, as the vast majority of us do every time we travel by road; or whether to use data and technology only to provide input into a human process of consideration and decision-making – as takes place in Rio when city agency staff consider Deep Thunder’s predictions alongside other data and use their own experience and that of their colleagues in determining how to respond.
In current discussions of the role of technology in the future of cities, we risk creating a divide between “soft” disciplines that deal with qualitative, subjective matters – social science and the arts for example; and “hard” disciplines that deal with data and technology – such as science, engineering, mathematics.
In the most polarised debates, opinion from “soft” disciplines is that “Smart cities” is a technology-driven approach that does not take human needs and nature into account, and does not recognise the variability and uncertainty inherent in city systems; and opinion from “hard” disciplines is that operational, design and policy decisions in cities are taken without due consideration of data that can be used to inform them and predict their outcomes. As Stephan Shakespeare wrote in the “Shakespeare Review of Public Sector Information“, “To paraphrase the great retailer Sir Terry Leahy, to run an enterprise without data is like driving by night with no headlights. And yet that is what government often does.”
There is no reason why these positions cannot be reconciled. In some domains “soft” and “hard” disciplines regularly collaborate. For example, the interior and auditory design of the Jaguar XF car, first manufactured in 2008, was designed by re-creating the driving experience in a simulator at the University of Warwick, and analysing the emotional response of test subjects using physiological sensors and data. Such techniques are now routinely used in product design. And many individuals have a breadth of knowledge that extends far beyond their core profession into a variety of areas of science and the arts.
But achieving reconciliation between all of the stakeholders involved in the vastly complex domain of cities – including the people who live in them, not just the academics, professionals and politicians who study, design, engineer and govern them – will not happen by default. It will only happen if we have an open and constructive debate about the capabilities and the limitations of data, information and technology; and if we are then able to communicate them in a way that expresses to everyone why Smarter City systems will improve their quality of life.

(“Which way to go?” by Peter Roome)
What’s next?
It’s astonishing and encouraging that we could use a model of individual consciousness to navigate the availability and value of data in the massively collective context of an urban scenario. To continue developing an understanding of the ability of information and technology to contribute to quality of life within cities, we need to expand that approach to explore the other dimensions we identified that affect perceptions of quality of life: culture, age and family status, for example; and within both larger and smaller scales of city context than the “district” scenario that we started with.
And we need to compare that approach to existing research work such as the Liveable Cities research collaboration between UK Universities that is establishing an evidence-based technique for assessing wellbeing; or the IBM Research initiative “SCRIBE” which seeks to define the meaning of and relationships between the many types of data that describe cities.
As a next step, the Urban Systems Collaborative attendees suggested that it would be useful to consider how people in different circumstances in cities use data, information and technology to take decisions: for example, city leaders, businesspeople, parents, hostel residents, commuters, hospital patients and so forth across the incredible variety of roles that we play in cities. You can find out more about how the Collaborative is taking this agenda forward on their website.
But this is not a debate that belongs only within the academic community or with technologists and scientists. Information and technology are changing the cities, society and economy that we live in and depend on. But that information results from data that in large part is created by all of our actions and activities as individuals, as we carry out our lives in cities, interacting with systems that from a technology perspective are increasingly instrumented, interconnected and intelligent. We are the ultimate stakeholders in the information economy, and we should seek to establish an equitable consensus for how our data is used; and that consensus should include an understanding and acceptance between all parties of both the capabilities and limitations of information and technology.
I’ve written before about the importance of telling stories that illustrate ways in which technology and information can change lives and communities for the better. The Community Lovers’ Guide to Birmingham is a great example of doing this. As cities such as Birmingham, Dublin and Chicago demonstrate what can be achieved by following a Smarter City agenda, I’m hoping that those involved can tell stories that will help other cities across the world to pursue these ideas themselves.
(This article summarises a discussion I chaired this week to explore the relationship between urban data, technology and quality of life at the Urban Systems Collaborative’s London workshop, organised by my ex-colleague, Colin Harrison, previously an IBM Distinguished Engineer responsible for much of our Smarter Cities strategy; and my current colleague, Jurij Paraszczak, Director of Industry Solutions and Smarter Cities for IBM Research. I’m grateful for the contributions of all of the attendees who took part. The article also appears on the Urban Systems Collaborative’s blog).


















")




{kind=link}