11 reasons computers can’t understand or solve our problems without human judgement
September 7, 2014 18 Comments

(Photo by Matt Gidley)
Why data is uncertain, cities are not programmable, and the world is not “algorithmic”.
Many people are not convinced that the Smart Cities movement will result in the use of technology to make places, communities and businesses in cities better. Outside their consumer enjoyment of smartphones, social media and online entertainment – to the degree that they have access to them – they don’t believe that technology or the companies that sell it will improve their lives.
The technology industry itself contributes significantly to this lack of trust. Too often we overstate the benefits of technology, or play down its limitations and the challenges involved in using it well.
Most recently, the idea that traditional processes of government should be replaced by “algorithmic regulation” – the comparison of the outcomes of public systems to desired objectives through the measurement of data, and the automatic adjustment of those systems by algorithms in order to achieve them – has been proposed by Tim O’Reilly and other prominent technologists.
These approaches work in many mechanical and engineering systems – the autopilots that fly planes or the anti-lock braking systems that we rely on to stop our cars. But should we extend them into human realms – how we educate our children or how we rehabilitate convicted criminals?
It’s clearly important to ask whether it would be desirable for our society to adopt such approaches. That is a complex debate, but my personal view is that in most cases the incredible technologies available to us today – and which I write about frequently on this blog – should not be used to take automatic decisions about such issues. They are usually more valuable when they are used to improve the information and insight available to human decision-makers – whether they are politicians, public workers or individual citizens – who are then in a better position to exercise good judgement.
More fundamentally, though, I want to challenge whether “algorithmic regulation” or any other highly deterministic approach to human issues is even possible. Quite simply, it is not.
It is true that our ability to collect, analyse and interpret data about the world has advanced to an astonishing degree in recent years. However, that ability is far from perfect, and strongly established scientific and philosophical principles tell us that it is impossible to definitively measure human outcomes from underlying data in physical or computing systems; and that it is impossible to create algorithmic rules that exactly predict them.
Sometimes automated systems succeed despite these limitations – anti-lock braking technology has become nearly ubiquitous because it is more effective than most human drivers at slowing down cars in a controlled way. But in other cases they create such great uncertainties that we must build in safeguards to account for the very real possibility that insights drawn from data are wrong. I do this every time I leave my home with a small umbrella packed in my bag despite the fact that weather forecasts created using enormous amounts of computing power predict a sunny day.

(No matter how sophisticated computer models of cities become, there are fundamental reasons why they will always be simplifications of reality. It is only by understanding those constraints that we can understand which insights from computer models are valuable, and which may be misleading. Image of Sim City by haljackey)
We can only understand where an “algorithmic” approach can be trusted; where it needs safeguards; and where it is wholly inadequate by understanding these limitations. Some of them are practical, and limited only by the sensitivity of today’s sensors and the power of today’s computers. But others are fundamental laws of physics and limitations of logical systems.
When technology companies assert that Smart Cities can create “autonomous, intelligently functioning IT systems that will have perfect knowledge of users’ habits” (as London School of Economics Professor Adam Greenfield rightly criticised in his book “Against the Smart City”), they are ignoring these challenges.
A blog published by the highly influential magazine Wired recently made similar overstatements: “The Universe is Programmable” argues that we should extend the concept of an “Application Programming Interface (API)” – a facility usually offered by technology systems to allow external computer programmes to control or interact with them – to every aspect of the world, including our own biology.
To compare complex, unpredictable, emergent biological and social systems to the very logical, deterministic world of computer software is at best a dramatic oversimplification. The systems that comprise the human body range from the armies of symbiotic microbes that help us digest food in our stomachs to the consequences of using corn syrup to sweeten food to the cultural pressure associated with “size 0” celebrities. Many of those systems can’t be well modelled in their own right, let alone deterministically related to each other; let alone formally represented in an accurate, detailed way by technology systems (or even in mathematics).
We should regret and avoid the hubris that leads to the distrust of technology by overstating its capability and failing to recognise its challenges and limitations. That distrust is a barrier that prevents us from achieving the very real benefits that data and technology can bring, and that have been convincingly demonstrated in the past.
For example, an enormous contribution to our knowledge of how to treat and prevent disease was made by John Snow who used data to analyse outbreaks of cholera in London in the 19th century. Snow used a map to correlate cases of cholera to the location of communal water pipes, leading to the insight that water-borne germs were responsible for spreading the disease. We wash our hands to prevent diseases spreading through germs in part because of what we would now call the “geospatial data analysis” performed by John Snow.
Many of the insights that we seek from analytic and smart city systems are human in nature, not physical or mathematical – for example identifying when and where to apply social care interventions in order to reduce the occurrence of emotional domestic abuse. Such questions are complex and uncertain: what is “emotional domestic abuse?” Is it abuse inflicted by a live-in boyfriend, or by an estranged husband who lives separately but makes threatening telephone calls? Does it consist of physical violence or bullying? And what is “bullying”?

(John Snow’s map of cholera outbreaks in 19th century London)
We attempt to create structured, quantitative data about complex human and social issues by using approximations and categorisations; by tolerating ranges and uncertainties in numeric measurements; by making subjective judgements; and by looking for patterns and clusters across different categories of data. Whilst these techniques can be very powerful, just how difficult it is to be sure what these conventions and interpretations should be is illustrated by the controversies that regularly arise around “who knew what, when?” whenever there is a high profile failure in social care or any other public service.
These challenges are not limited to “high level” social, economic and biological systems. In fact, they extend throughout the worlds of physics and chemistry into the basic nature of matter and the universe. They fundamentally limit the degree to which we can measure the world, and our ability to draw insight from that information.
By being aware of these limitations we are able to design systems and practises to use data and technology effectively. We know more about the weather through modelling it using scientific and mathematical algorithms in computers than we would without those techniques; but we don’t expect those forecasts to be entirely accurate. Similarly, supermarkets can use data about past purchases to make sufficiently accurate predictions about future spending patterns to boost their profits, without needing to predict exactly what each individual customer will buy.
We underestimate the limitations and flaws of these approaches at our peril. Whilst Tim O’Reilly cites several automated financial systems as good examples of “algorithmic regulation”, the financial crash of 2008 showed the terrible consequences of the thoroughly inadequate risk management systems used by the world’s financial institutions compared to the complexity of the system that they sought to profit from. The few institutions that realised that market conditions had changed and that their models for risk management were no longer valid relied instead on the expertise of their staff, and avoided the worst affects. Others continued to rely on models that had started to produce increasingly misleading guidance, leading to the recession that we are only now emerging from six years later, and that has damaged countless lives around the world.
Every day in their work, scientists, engineers and statisticians draw conclusions from data and analytics, but they temper those conclusions with an awareness of their limitations and any uncertainties inherent in them. By taking and communicating such a balanced and informed approach to applying similar techniques in cities, we will create more trust in these technologies than by overstating their capabilities.
What follows is a description of some of the scientific, philosophical and practical issues that lead inevitability to uncertainty in data, and to limitations in our ability to draw conclusions from it:
- Three reasons why we can’t measure data perfectly;
- Three limits to our ability to analyse data and draw insights from it;
- Five reasons why the human world is messy, unpredictable, and can’t be perfectly described using data and logic.
But I’ll finish with an explanation of why we can still draw great value from data and analytics if we are aware of those issues and take them properly into account.
Three reasons why we can’t measure data perfectly

(How Heisenberg’s Uncertainty Principle results from the dual wave/particle nature of matter. Explanation by HyperPhysics at Georgia State University)
1. Heisenberg’s Uncertainty Principle and the fundamental impossibility of knowing everything about anything
Heisenberg’s Uncertainty Principle is a cornerstone of Quantum Mechanics, which, along with General Relativity, is one of the two most fundamental theories scientists use to understand our world. It defines a limit to the precision with which certain pairs of properties of the basic particles which make up the world – such as protons, neutrons and electrons – can be known at the same time. For instance, the more accurately we measure the position of such particles, the more uncertain their speed and direction of movement become.
The explanation of the Uncertainty Principle is subtle, and lies in the strange fact that very small “particles” such as electrons and neutrons also behave like “waves”; and that “waves” like beams of light also behave like very small “particles” called “photons“. But we can use an analogy to understand it.
In order to measure something, we have to interact with it. In everyday life, we do this by using our eyes to measure lightwaves that are created by lightbulbs or the sun and that then reflect off objects in the world around us.
But when we shine light on an object, what we are actually doing is showering it with billions of photons, and observing the way that they scatter. When the object is quite large – a car, a person, or a football – the photons are so small in comparison that they bounce off without affecting it. But when the object is very small – such as an atom – the photons colliding with it are large enough to knock it out of its original position. In other words, measuring the current position of an object involves a collision which causes it to move in a random way.
This analogy isn’t exact; but it conveys the general idea. (For a full explanation, see the figure and link above). Most of the time, we don’t notice the effects of Heisenberg’s Uncertainty Principle because it applies at extremely small scales. But it is perhaps the most fundamental law that asserts that “perfect knowledge” is simply impossible; and it illustrates a wider point that any form of measurement or observation in general affects what is measured or observed. Sometimes the effects are negligible, but often they are not – if we observe workers in a time and motion study, for example, we need to be careful to understand the effect our presence and observations have on their behaviour.
2. Accuracy, precision, noise, uncertainty and error: why measurements are never fully reliable
Outside the world of Quantum Mechanics, there are more practical issues that limit the accuracy of all measurements and data.

(A measurement of the electrical properties of a superconducting device from my PhD thesis. Theoretically, the behaviour should appear as a smooth, wavy line; but the experimental measurement is affected by noise and interference that cause the signal to become “fuzzy”. In this case, the effects of noise and interference – the degree to which the signal appears “fuzzy” – are relatively small compared to the strength of the signal, and the device is usable)
We live in a “warm” world – roughly 300 degrees Celsius above what scientists call “absolute zero“, the coldest temperature possible. What we experience as warmth is in fact movement: the atoms from which we and our world are made “jiggle about” – they move randomly. When we touch a hot object and feel pain it is because this movement is too violent to bear – it’s like being pricked by billions of tiny pins.
This random movement creates “noise” in every physical system, like the static we hear in analogue radio stations or on poor quality telephone connections.
We also live in a busy world, and this activity leads to other sources of noise. All electronic equipment creates electrical and magnetic fields that spread beyond the equipment itself, and in turn affect other equipment – we can hear this as a buzzing noise when we leave smartphones near radios.
Generally speaking, all measurements are affected by random noise created by heat, vibrations or electrical interference; are limited by the precision and accuracy of the measuring devices we use; and are affected by inconsistencies and errors that arise because it is always impossible to completely separate the measurement we want to make from all other environmental factors.
Scientists, engineers and statisticians are familiar with these challenges, and use techniques developed over the course of more than a century to determine and describe the degree to which they can trust and rely on the measurements they make. They do not claim “perfect knowledge” of anything; on the contrary, they are diligent in describing the unavoidable uncertainty that is inherent in their work.
3. The limitations of measuring the natural world using digital systems
One of the techniques we’ve adopted over the last half century to overcome the effects of noise and to make information easier to process is to convert “analogue” information about the real world (information that varies smoothly) into digital information – i.e. information that is expressed as sequences of zeros and ones in computer systems.

(When analogue signals are amplified, so is the noise that they contain. Digital signals are interpreted using thresholds: above an upper threshold, the signal means “1”, whilst below a lower threshold, the signal means “0”. A long string of “0”s and “1”s can be used to encode the same information as contained in analogue waves. By making the difference between the thresholds large compared to the level of signal noise, digital signals can be recreated to remove noise. Further explanation and image by Science Aid)
This process involves a trade-off between the accuracy with which analogue information is measured and described, and the length of the string of digits required to do so – and hence the amount of computer storage and processing power needed.
This trade-off can be clearly seen in the difference in quality between an internet video viewed on a smartphone over a 3G connection and one viewed on a high definition television using a cable network. Neither video will be affected by the static noise that affects weak analogue television signals, but the limited bandwidth of a 3G connection dramatically limits the clarity and resolution of the image transmitted.
The Nyquist–Shannon sampling theorem defines this trade-off and the limit to the quality that can be achieved in storing and processing digital information created from analogue sources. It determines the quality of digital data that we are able to create about any real-world system – from weather patterns to the location of moving objects to the fidelity of sound and video recordings. As computers and communications networks continue to grow more powerful, the quality of digital information will improve, but it will never be a perfect representation of the real world.
Three limits to our ability to analyse data and draw insights from it
1. Gödel’s Incompleteness Theorem and the inconsistency of algorithms
Kurt Gödel’s Incompleteness Theorem sets a limit on what can be achieved by any “closed logical system”. Examples of “closed logical systems” include computer programming languages, any system for creating algorithms – and mathematics itself.
We use “closed logical systems” whenever we create insights and conclusions by combining and extrapolating from basic data and facts. This is how all reporting, calculating, business intelligence, “analytics” and “big data” technologies work.
Gödel’s Incompleteness Theorem proves that any closed logical system can be used to create conclusions that it is not possible to show are true or false using the same system. In other words, whilst computer systems can produce extremely useful information, we cannot rely on them to prove that that information is completely accurate and valid. We have to do that ourselves.
Gödel’s theorem doesn’t stop computer algorithms that have been verified by humans using the scientific method from working; but it does mean that we can’t rely on computers to both generate algorithms and guarantee their validity.
2. The behaviour of many real-world systems can’t be reduced analytically to simple rules
Many systems in the real-world are complex: they cannot be described by simple rules that predict their behaviour based on measurements of their initial conditions.
A simple example is the “three body problem“. Imagine a sun, a planet and a moon all orbiting each other. The movement of these three objects is governed by the force of gravity, which can be described by relatively simple mathematical equations. However, even with just three objects involved, it is not possible to use these equations to directly predict their long-term behaviour – whether they will continue to orbit each other indefinitely, or will eventually collide with each other, or spin off into the distance.
(A computer simulation by Hawk Express of a Belousov–Zhabotinsky reaction, in which reactions between liquid chemicals create oscillating patterns of colour. The simulation is carried out using “cellular automata” a technique based on a grid of squares which can take different colours. In each “turn” of the simulation, like a turn in a board game, the colour of each square is changed using simple rules based on the colours of adjacent squares. Such simulations have been used to reproduce a variety of real-world phenomena)
As Stephen Wolfram argued in his controversial book “A New Kind of Science” in 2002, we need to take a different approach to understanding such complex systems. Rather than using mathematics and logic to analyse them, we need to simulate them, often using computers to create models of the elements from which complex systems are composed, and the interactions between them. By running simulations based on a large number of starting points and comparing the results to real-world observations, insights into the behaviour of the real-world system can be derived. This is how weather forecasts are created, for example.
But as we all know, weather forecasts are not always accurate. Simulations are approximations to real-world systems, and their accuracy is restricted by the degree to which digital data can be used to represent a non-digital world. For this reason, conclusions and predictions drawn from simulations are usually “average” or “probable” outcomes for the system as a whole, not precise predictions of the behaviour of the system or any individual element of it. This is why weather forecasts are often wrong; and why they predict likely levels of rain and windspeed rather than the shape and movement of individual clouds.
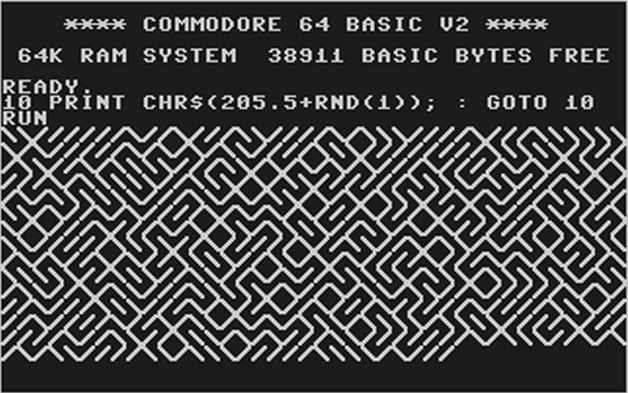
(A simple and famous example of a computer programme that never stops running because it calls itself. The output continually varies by printing out characters based on random number generation. Image by Prosthetic Knowledge)
3. Some problems can’t be solved by computing machines
If I consider a simple question such as “how many letters are in the word ‘calculation’?”, I can easily convince myself that a computer programme could be written to answer the question; and that it would find the answer within a relatively short amount of time. But some problems are much harder to solve, or can’t even be solved at all.
For example, a “Wang Tile” (see image below) is a square tile formed from four triangles of different colours. Imagine that you have bought a set of tiles of various colour combinations in order to tile a wall in a kitchen or bathroom. Given the set of tiles that you have bought, is it possible to tile your wall so that triangles of the same colour line up to each other, forming a pattern of “Wang Tile” squares?
In 1966 Robert Berger proved that no algorithm exists that can answer that question. There is no way to solve the problem – or to determine how long it will take to solve the problem – without actually solving it. You just have to try to tile the room and find out the hard way.
One of the most famous examples of this type of problem is the “halting problem” in computer science. Some computer programmes finish executing their commands relatively quickly. Others can run indefinitely if they contain a “loop” instruction that never ends. For others which contain complex sequences of loops and calls from one section of code to another, it may be very hard to tell whether the programme finishes quickly, or takes a long time to complete, or never finishes its execution at all.
Alan Turing, one of the most important figures in the development of computing, proved in 1936 that a general algorithm to determine whether or not any computer programme finishes its execution does not exist. In other words, whilst there are many useful computer programmes in the world, there are also problems that computer programmes simply cannot solve.

(A set of Wang Tiles, and a pattern of coloured squares created by tiling them. Given any random set of tiles of different colour combinations, there is no set of rules that can be relied on to determine whether a valid pattern of coloured squares can be created from them. Sometimes, you have to find out by trial and error. Images from Wikipedia)
Five reasons why the human world is messy, unpredictable, and can’t be perfectly described using data and logic
1. Our actions create disorder
The 2nd Law of Thermodynamics is a good candidate for the most fundamental law of science. It states that as time progresses, the universe becomes more disorganised. It guarantees that ultimately – in billions of years – the Universe will die as all of the energy and activity within it dissipates.
An everyday practical consequence of this law is that every time we act to create value – building a shed, using a car to get from one place to another, cooking a meal – our actions eventually cause a greater amount of disorder to be created as a consequence – as noise, pollution, waste heat or landfill refuse.
For example, if I spend a day building a shed, then to create that order and value from raw materials, I consume structured food and turn it into sewage. Or if I use an electric forklift to stack a pile of boxes, I use electricity that has been created by burning structured coal into smog and ash.
So it is literally impossible to create a “perfect world”. Whenever we act to make a part of the world more ordered, we create disorder elsewhere. And ultimately – thankfully, long after you and I are dead – disorder is all that will be left.
2. The failure of Logical Atomism: why the human world can’t be perfectly described using data and logic
In the 20th Century two of the most famous and accomplished philosophers in history, Bertrand Russell and Ludwig Wittgenstein, invented “Logical Atomism“, a theory that the entire world could be described by using “atomic facts” – independent and irreducible pieces of knowledge – combined with logic.
But despite 40 years of work, these two supremely intelligent people could not get their theory to work: “Logical Atomism” failed. It is not possible to describe our world in that way.
One cause of the failure was the insurmountable difficulty of identifying truly independent, irreducible atomic facts. “The box is red” and “the circle is blue”, for example, aren’t independent or irreducible facts for many reasons. “Red” and “blue” are two conventions of human language used to describe the perceptions created when electro-magnetic waves of different frequencies arrive at our retinas. In other words, they depend on and relate to each other through a number of sophisticated systems.
Despite centuries of scientific and philosophical effort, we do not have a complete understanding of how to describe our world at its most basic level. As physicists have explored the world at smaller and smaller scales, Quantum Mechanics has emerged as the most fundamental theory for describing it – it is the closest we have come to finding the “irreducible facts” that Russell and Wittgenstein were looking for. But whilst the mathematical equations of Quantum Mechanics predict the outcomes of experiments very well, after nearly a century, physicists still don’t really agree about what those equations mean. And as we have already seen, Heisenberg’s Uncertainty Principle prevents us from ever having perfect knowledge of the world at this level.
Perhaps the most important failure of logical atomism, though, was that it proved impossible to use logical rules to turn “facts” at one level of abstraction – for example, “blood cells carry oxygen”, “nerves conduct electricity”, “muscle fibres contract” – into facts at another level of abstraction – such as “physical assault is a crime”. The human world and the things that we care about can’t be described using logical combinations of “atomic facts”. For example, how would you define the set of all possible uses of a screwdriver, from prising the lids off paint tins to causing a short-circuit by jamming it into a switchboard?
Our world is messy, subjective and opportunistic. It defies universal categorisation and logical analysis.

(A Pescheria in Bari, Puglia, where a fish-market price information service makes it easier for local fisherman to identify the best buyers and prices for their daily catch. Photo by Vito Palmi)
3. The importance and inaccessibility of “local knowledge”
Because the tool we use for calculating and agreeing value when we exchange goods and services is money, economics is the discipline that is often used to understand the large-scale behaviour of society. We often quantify the “growth” of society using economic measures, for example.
But this approach is notorious for overlooking social and environmental characteristics such as health, happiness and sustainability. Alternatives exist, such as the Social Progress Index, or the measurement framework adopted by the United Nations 2014 Human Development Report on world poverty; but they are still high level and abstract.
Such approaches struggle to explain localised variations, and in particular cannot predict the behaviours or outcomes of individual people with any accuracy. This “local knowledge problem” is caused by the fact that a great deal of the information that determines individual actions is personal and local, and not measurable at a distance – the experienced eye of the fruit buyer assessing not just the quality of the fruit but the quality of the farm and farmers that produce it, as a measure of the likely consistency of supply; the emotional attachments that cause us to favour one brand over another; or the degree of community ties between local businesses that influence their propensity to trade with each other.
“Sharing economy” business models that use social media and reputation systems to enable suppliers and consumers of goods and services to find each other and transact online are opening up this local knowledge to some degree. Local food networks, freecycling networks, and land-sharing schemes all use this technology to the benefit of local communities whilst potentially making information about detailed transactions more widely available. And to some degree, the human knowledge that influences how transactions take place can be encoded in “expert systems” which allow computer systems to codify the quantitative and heuristic rules by which people take decisions.
But these technologies are only used in a subset of the interactions that take place between people and businesses across the world, and it is unlikely that they’ll become ubiquitous in the foreseeable future (or that we would want them to become so). Will we ever reach the point where prospective house-buyers delegate decisions about where to live to computer programmes operating in online marketplaces rather than by visiting places and imagining themselves living there? Will we somehow automate the process of testing the freshness of fish by observing the clarity of their eyes and the freshness of their smell before buying them to cook and eat?
In many cases, while technology may play a role introducing potential buyers and sellers of goods and services to each other, it will not replace – or predict – the human behaviours involved in the transaction itself.
(Medway Youth Trust use predictive and textual analytics to draw insight into their work helping vulnerable children. They use technology to inform expert case workers, not to take decisions on their behalf.)
4. “Wicked problems” cannot be described using data and logic
Despite all of the challenges associated with problems in mathematics and the physical sciences, it is nevertheless relatively straightforward to frame and then attempt to solve problems in those domains; and to determine whether the resulting solutions are valid.
As the failure of Logical Atomism showed, though, problems in the human domain are much more difficult to describe in any systematic, complete and precise way – a challenge known as the “frame problem” in artificial intelligence. This is particularly true of “wicked problems” – challenges such as social mobility or vulnerable families that are multi-faceted, and consist of a variety of interdependent issues.
Take job creation, for example. Is that best accomplished through creating employment in taxpayer-funded public sector organisations? Or by allowing private-sector wealth to grow, creating employment through “trickle-down” effects? Or by maximising overall consumer spending power as suggested by “middle-out” economics? All of these ideas are described not using the language of mathematics or other formal logical systems, but using natural human language which is subjective and inconsistent in use.
The failure of Logical Atomism to fully represent such concepts in formal logical systems through which truth and falsehood can be determined with certainty emphasises what we all understand intuitively: there is no single “right” answer to many human problems, and no single “right” action in many human situations.

(An electricity bill containing information provided by OPower comparing one household’s energy usage to their neighbours. Image from Grist)
5. Behavioural economics and the caprice of human behaviour
“Behavioural economics” attempts to predict the way that humans behave when taking choices that have a measurable impact on them – for example, whether to put the washing machine on at 5pm when electricity is expensive, or at 11pm when it is cheap.
But predicting human behaviour is notoriously unreliable.
For example, in a smart water-meter project in Dubuque, Iowa, households that were told how their water conservation compared to that of their near neighbours were found to be twice as likely to take action to improve their efficiency as those who were only told the details of their own water use. In other words, people who were given quantified evidence that they were less responsible water user than their neighbours changed their behaviour. OPower have used similar techniques to help US households save 1.9 terawatt hours of power simply by including a report based on data from smart meters in a printed letter sent with customers’ electricity bills.
These are impressive achievements; but they are not always repeatable. A recycling scheme in the UK that adopted a similar approach found instead that it lowered recycling rates across the community: households who learned that they were putting more effort into recycling than their neighbours asked themselves “if my neighbours aren’t contributing to this initiative, then why should I?”
Low carbon engineering technologies like electric vehicles have clearly defined environmental benefits and clearly defined costs. But most Smart Cities solutions are less straightforward. They are complex socio-technical systems whose outcomes are emergent. Our ability to predict their performance and impact will certainly improve as more are deployed and analysed, and as University researchers, politicians, journalists and the public assess them. But we will never predict individual actions using these techniques, only the average statistical behaviour of groups of people. This can be seen from OPower’s own comparison of their predicted energy savings against those actually achieved – the predictions are good, but the actual behaviour of OPower’s customers shows a high degree of apparently random variation. Those variations are the result of the subjective, unpredictable and sometimes irrational behaviour of real people.
We can take insight from Behavioural Economics and other techniques for analysing human behaviour in order to create appropriate strategies, policies and environments that encourage the right outcomes in cities; but none of them can be relied on to give definitive solutions to any individual person or situation. They can inform decision-making, but are always associated with some degree of uncertainty. In some cases, the uncertainty will be so small as to be negligible, and the predictions can be treated as deterministic rules for achieving the desired outcome. But in many cases, the uncertainty will be so great that predictions can only be treated as general indications of what might happen; whilst individual actions and outcomes will vary greatly.
(Of course it is impossible to predict individual criminal actions as portrayed in the film “Minority Report”. But is is very possible to analyse past patterns of criminal activity, compare them to related data such as weather and social events, and predict the likelihood of crimes of certain types occurring in certain areas. Cities such as Memphis and Chicago have used these insights to achieve significant reductions in crime)
Learning to value insight without certainty
Mathematics and digital technology are incredibly powerful; but they will never perfectly and completely describe and predict our world in human terms. In many cases, our focus for using them should not be on automation: it should be on the enablement of human judgement through better availability and communication of information. And in particular, we should concentrate on communicating accurately the meaning of information in the context of its limitations and uncertainties.
There are exceptions where we automate systems because of a combination of a low-level of uncertainty in data and a large advantage in acting autonomously on it. For example, anti-lock braking systems save lives by using automated technology to take thousands of decisions more quickly than most humans would realise that even a single decision needed to be made; and do so based on data with an extremely low degree of uncertainty.
But the most exciting opportunity for us all is to learn to become sophisticated users of information that is uncertain. The results of textual analysis of sentiment towards products and brands expressed in social media are far from certain; but they are still of great value. Similar technology can extract insights from medical research papers, case notes in social care systems, maintenance logs of machinery and many other sources. Those insights will rarely be certain; but properly assessed by people with good judgement they can still be immensely valuable.
This is a much better way to understand the value of technology than ideas like “perfect knowledge” and “algorithmic regulation”. And it is much more likely that people will trust the benefits that we claim new technologies can bring if we are open about their limitations. People won’t use technologies that they don’t trust; and they won’t invest their money in them or vote for politicians who say they’ll spend their taxes on it.
Thankyou to Richard Brown and Adrian McEwen for discussions on Twitter that helped me to prepare this article. A more in-depth discussion of some of the scientific and philosophical issues I’ve described, and an exploration of the nature of human intelligence and its non-deterministic characteristics, can be found in the excellent paper “Answering Descartes: Beyond Turing” by Stuart Kauffman published by MIT press.












")


{kind=link}