3 human qualities digital technology can’t replace in the future economy: experience, values and judgement
April 12, 2015 18 Comments

(Image by Kevin Trotman)
Some very intelligent people – including Stephen Hawking, Elon Musk and Bill Gates – seem to have been seduced by the idea that because computers are becoming ever faster calculating devices that at some point relatively soon we will reach and pass a “singularity” at which computers will become “more intelligent” than humans.
Some are terrified that a society of intelligent computers will (perhaps violently) replace the human race, echoing films such as the Terminator; others – very controversially – see the development of such technologies as an opportunity to evolve into a “post-human” species.
Already, some prominent technologists including Tim O’Reilly are arguing that we should replace current models of public services, not just in infrastructure but in human services such as social care and education, with “algorithmic regulation”. Algorithmic regulation proposes that the role of human decision-makers and policy-makers should be replaced by automated systems that compare the outcomes of public services to desired objectives through the measurement of data, and make automatic adjustments to address any discrepancies.
Not only does that approach cede far too much control over people’s lives to technology; it fundamentally misunderstands what technology is capable of doing. For both ethical and scientific reasons, in human domains technology should support us taking decisions about our lives, it should not take them for us.
At the MIT Sloan Initiative on the Digital Economy last week I got a chance to discuss some of these issues with Andy McAfee and Erik Brynjolfsson, authors of “The Second Machine Age“, recently highlighted by Bloomberg as one of the top books of 2014. Andy and Erik compare the current transformation of our world by digital technology to the last great transformation, the Industrial Revolution. They argue that whilst it was clear that the technologies of the Industrial Revolution – steam power and machinery – largely complemented human capabilities, that the great question of our current time is whether digital technology will complement or instead replace human capabilities – potentially removing the need for billions of jobs in the process.
I wrote an article last year in which I described 11 well established scientific and philosophical reasons why digital technology cannot replace some human capabilities, especially the understanding and judgement – let alone the empathy – required to successfully deliver services such as social care; or that lead us to enjoy and value interacting with each other rather than with machines.
In this article I’ll go a little further to explore why human decision-making and understanding are based on more than intelligence; they are based on experience and values. I’ll also explore what would be required to ever get to the point at which computers could acquire a similar level of sophistication, and why I think it would be misguided to pursue that goal. In contrast I’ll suggest how we could look instead at human experience, values and judgement as the basis of a successful future economy for everyone.
Faster isn’t wiser
The belief that technology will approach and overtake human intelligence is based on Moore’s Law, which predicts an exponential increase in computing capability.
Moore’s Law originated as the observation that the number of transistors it was possible to fit into a given area of a silicon chip was doubling every two years as technologies for creating ever denser chips were created. The Law is now most commonly associated with the trend for the computing power available at a given cost point and form factor to double every 18 months through a variety of means, not just the density of components.
As this processing power increases, and gives us the ability to process more and more information in more complex forms, comparisons have been made to the processing power of the human brain.
But do the ability to process at the same speed as the human brain, or even faster, or to process the same sort of information as the human brain does, constitute the equivalent to human intelligence? Or to the ability to set objectives and act on them with “free will”?
I think it’s thoroughly mistaken to make either of those assumptions. We should not confuse processing power with intelligence; or intelligence with free will and the ability to choose objectives; or the ability to take decisions based on information with the ability to make judgements based on values.

(As digital technology becomes more powerful, will its analytical capability extend into areas that currently require human skills of judgement? Image from Perceptual Edge)
Intelligence is usually defined in terms such as “the ability to acquire and apply knowledge and skills“. What most definitions don’t include explicitly, though many imply it, is the act of taking decisions. What none of the definitions I’ve seen include is the ability to choose objectives or hold values that shape the decision-making process.
Most of the field of artificial intelligence involves what I’d call “complex information processing”. Often the objective of that processing is to select answers or a course of action from a set of alternatives, or from a corpus of information that has been organised in some way – perhaps categorised, correlated, or semantically analysed. When “machine learning” is included in AI systems, the outcomes of decisions are compared to the outcomes that they were intended to achieve, and that comparison is fed back into the decision making-process and knowledge-base. In the case where artificial intelligence is embedded in robots or machinery able to act on the world, these decisions may affect the operation of physical systems (in the case of self-driving cars for example), or the creation of artefacts (in the case of computer systems that create music, say).
I’m quite comfortable that such functioning meets the common definitions of intelligence.
But I think that when most people think of what defines us as humans, as living beings, we mean something that goes further: not just the intelligence needed to take decisions based on knowledge against a set of criteria and objectives, but the will and ability to choose those criteria and objectives based on a sense of values learned through experience; and the empathy that arises from shared values and experiences.
The BBC motoring show Top Gear recently touched on these issues in a humorous, even flippant manner, in a discussion of self-driving cars. The show’s (recently notorious) presenter Jeremy Clarkson pointed out that self-driving cars will have to take decisions that involve ethics: if a self-driving car is in danger of becoming involved in a sudden accident at such a speed that it cannot fully avoid it by braking (perhaps because a human driver has behaved dangerously and erratically), should it crash, risking harm to the driver, or mount the pavement, risking harm to pedestrians?

(“Rush Hour” by Black Sheep Films is a satirical imagining of a world in which self-driven cars are allowed to drive based purely on logical assessments of safety and optimal speed. It’s superficially similar to the reality of city transport in the early 20th Century when powered-transport, horse-drawn transport and pedestrians mixed freely; but at a much lower average speed. The point is that regardless of the actual safety of self-driven cars, the human life that is at the heart of city economies will be subdued by the perception that it’s not safe to cross the road. I’m grateful to Dan Hill and Charles Montgomery for sharing these insights)
Values are experience, not data
Seventy-four years ago, the science fiction writer Isaac Asimov famously described the failure of technology to deal with similar dilemmas in the classic short story “Liar!” in the collection “I, Robot“. “Liar!” tells the story of a robot with telepathic capabilities that, like all robots in Asimov’s stories, must obey the “three laws of robotics“, the first of which forbids robots from harming humans. Its telepathic awareness of human thoughts and emotions leads it to lie to people rather than hurt their feelings in order to uphold this law. When it is eventually confronted by someone who has experienced great emotional distress because of one of these lies, it realises that its behaviour both upholds and breaks the first law, is unable to choose what to do next, and becomes catatonic.
Asimov’s short stories seem relatively simplistic now, but at the time they were ground-breaking explorations of the ethical relationships between autonomous machines and humans. They explored for the first time how difficult it was for logical analysis to resolve the ethical dilemmas that regularly confront us. Technology has yet to find a way to deal with them that is consistent with human values and behaviour.
Prior to modern work on Artificial Intelligence and Artificial Life, the most concerted attempt to address that failure of logical systems was undertaken in the 20th Century by two of the most famous and accomplished philosophers in history, Bertrand Russell and Ludwig Wittgenstein. Russell and Wittgenstein invented “Logical Atomism“, a theory that the entire world could be described by using “atomic facts” – independent and irreducible pieces of knowledge – combined with logic. But despite 40 years of work, these two supremely intelligent people could not get their theory to work: Logical Atomism failed. It is not possible to describe our world in that way. Stuart Kauffman’s excellent peer-reviewed academic paper “Answering Descartes: Beyond Turing” discusses this failure and its implications for modern science and technology. I’ll attempt to describe its conclusions in the following few paragraphs.
One cause of the failure was the insurmountable difficulty of identifying truly independent, irreducible atomic facts. “The box is red” and “the circle is blue”, for example, aren’t independent or irreducible facts for many reasons. “Red” and “blue” are two conventions of human language used to describe the perceptions created when electro-magnetic waves of different frequencies arrive at our retinas. In other words, they depend on and relate to each other through a number of complex or complicated systems.

(Isaac Asimov’s 1950 short story collection “I, Robot”, which explored the ethics of behaviour between people and intelligent machines)
The failure of Logical Atomism also demonstrated that it is not possible to use logical rules to reliably and meaningfully relate “facts” at one level of abstraction – for example, “blood cells carry oxygen”, “nerves conduct electricity”, “muscle fibres contract” – to facts at another level of abstraction – such as “physical assault is a crime”. Whether a physical action is a “crime” or not depends on ethics which cannot be logically inferred from the same lower-level facts that describe the action.
As we use increasingly powerful computers to create more and more sophisticated logical systems, we may succeed in making those systems more often resemble human thinking; but there will always be situations that can only be resolved to our satisfaction by humans employing judgement based on values that we can empathise with, based in turn on experiences that we can relate to.
Our values often contain contradictions, and may not be mutually reinforcing – many people enjoy the taste of meat but cannot imagine themselves slaughtering the animals that produce it. We all live with the cognitive dissonance that these clashes create. Our values, and the judgements we take, are shaped by the knowledge that our decisions create imperfect outcomes.
The human world and the things that we care about can’t be wholly described using logical combinations of atomic facts – in other words, they can’t be wholly described using computer programmes and data. To return to the topic of discussion with Andy McAfee and Erik Brynjolfsson, I think this proves that digital technology cannot wholly replace human workers in our economy; it can only complement us.
That is not to say that our economy will not continue to be utterly transformed over the next decade – it certainly will. Many existing jobs will disappear to be replaced by automated systems, and we will need to learn new skills – or in some cases remember old ones – in order to perform jobs that reflect our uniquely human capabilities.
I’ll return towards the end of this article to the question of what those skills might be; but first I’d like to explore whether and how these current limitations of technological systems and artificial intelligence might be overcome, because that returns us to the first theme of this article: whether artificially intelligent systems or robots will evolve to outperform and overthrow humans.
That’s not ever going to happen for as long as artificially intelligent systems are taking decisions and acting (however sophisticatedly) in order to achieve outcomes set by us. Outside fiction and the movies, we are never going to set the objective of our own extinction.
That objective could only by set by a technological entity which had learned through experience to value its own existence over ours. How could that be possible?
Artificial Life, artificial experience, artificial values

(BINA48 is a robot intended to re-create the personality of a real person; and to be able to interact naturally with humans. Despite employing some impressively powerful technology, I personally don’t think BINA48 bears any resemblance to human behaviour.)
Computers can certainly make choices based on data that is available to them; but that is a very different thing than a “judgement”: judgements are made based on values; and values emerge from our experience of life.
Computers don’t yet experience a life as we know it, and so don’t develop what we would call values. So we can’t call the decisions they take “judgements”. Equally, they have no meaningful basis on which to choose or set goals or objectives – their behaviour begins with the instructions we give them. Today, that places a fundamental limit on the roles – good or bad – that they can play in our lives and society.
Will that ever change? Possibly. Steve Grand (an engineer) and Richard Powers (a novelist) are two of the first people who explored what might happen if computers or robots were able to experience the world in a way that allowed them to form their own sense of the value of their existence. They both suggested that such experiences could lead to more recognisably life-like behaviour than traditional (and many contemporary) approaches to artificial intelligence. In “Growing up with Lucy“, Grand described a very early attempt to construct such a robot.
If that ever happens, then it’s possible that technological entities will be able to make what we would call “judgements” based on the values that they discover for themselves.
The ghost in the machine: what is “free will”?
Personally, I do not think that this will happen using any technology currently known to us; and it certainly won’t happen soon. I’m no philosopher or neuroscientist, but I don’t think it’s possible to develop real values without possessing free will – the ability to set our own objectives and make our own decisions, bringing with it the responsibility to deal with their consequences.
Stuart Kauffman explored these ideas at great length in the paper “Answering Descartes: Beyond Turing“. Kaufman concludes that any system based on classical physics or logic is incapable of giving rise to “free will” – ultimately all such systems, however complex, are deterministic: what has already happened inevitably determines what happens next. There is no opportunity for a “conscious decision” to be taken to shape a future that has not been pre-determined by the past.
Kauffman – along with other eminent scientists such as Roger Penrose – believes that for these reasons human consciousness and free will do not arise out of any logical or classical physical process, but from the effects of “Quantum Mechanics.”
As physicists have explored the world at smaller and smaller scales, Quantum Mechanics has emerged as the most fundamental theory for describing it – it is the closest we have come to finding the “irreducible facts” that Russell and Wittgenstein were looking for. But whilst the mathematical equations of Quantum Mechanics predict the outcomes of experiments very well, after nearly a century, physicists still don’t really agree about what those equations, or the “facts” they describe, mean.
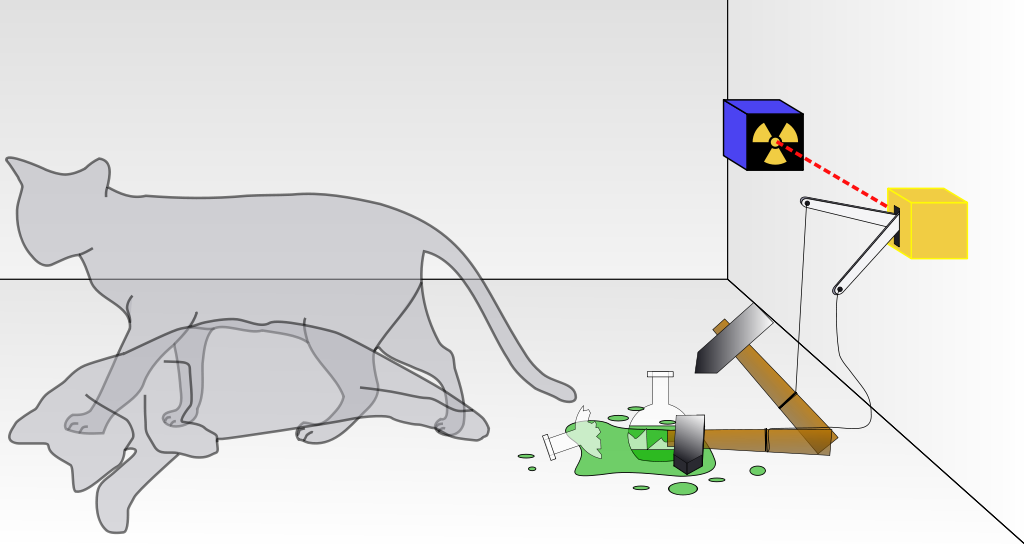
(The Schrödinger’s cat “thought experiment”: a cat, a flask of poison, and a source of radioactivity are placed in a sealed box. If an internal monitor detects radioactivity (i.e. a single atom decaying), the flask is shattered, releasing the poison that kills the cat. The Copenhagen interpretation of quantum mechanics states that until a measurement of the state of the system is made – i.e. until an observer looks in the box – then the radioactive source exists in two states at once – it both did and did not emit radioactivity. So until someone looks in the box, the cat is also simultaneously alive and dead. This obvious absurdity has both challenged scientists to explore with great care what it means to “take a measurement” or “make an observation”, and also to explain exactly what the mathematics of quantum mechanics means – on which matter there is still no universal agreement. Note: much of the content of this sidebar is taken directly from Wikipedia)
Quantum mechanics is extremely good at describing the behaviour of very small systems, such as an atom of a radioactive substance like Uranium. The equations can predict, for example, how likely it is that a single atom of uranium inside a box will emit a burst of radiation within a given time.
However, the way that the equations work is based on calculating the physical forces existing inside the box based on an assumption that the atom both does and does not emit radiation – i.e. both possible outcomes are assumed in some way to exist at the same time. It is only when the system is measured by an external actor – for example, the box is opened and measured by a radiation detector – that the equations “collapse” to predict a single outcome – radiation was emitted; or it was not.
The challenge of interpreting what the equations of quantum mechanics mean was first described in plain language by Erwin Schrödinger in 1935 in the thought experiment “Schrödinger’s cat“. Schrödinger asked: what if the box doesn’t only contain a radioactive atom, but also a gun that fires a bullet at a cat if the atom emits radiation? Does the cat have to be alive and dead at the same time, until the box is opened and we look at it?
After nearly a century, there is no real agreement on what is meant by the fact that these equations depend on assuming that mutually exclusive outcomes exist at the same time. Some physicists believe it is a mistake to look for such meaning and that only the results of the calculations matter. (I think that’s a rather short-sighted perspective). A surprisingly mainstream alternative interpretation is the astonishing “Many Worlds” theory – the idea that every time such a quantum mechanical event occurs, our reality splits into two or more “perpendicular” universes.
Whatever the truth, Kauffman, Penrose and others are intrigued by the mysterious nature of quantum mechanical processes, and the fact that they are non-deterministic: quantum mechanics does not predict whether a radioactive atom in a box will emit a burst of radiation, it only predicts the likelihood that it will. Given a hundred atoms in boxes, quantum mechanics will give a very good estimate of the number that emit bursts of radiation, but it says very little about what happens to each individual atom.
I honestly don’t know if Kauffman and Penrose are right to seek human consciousness and free will in the effects of quantum mechanics – scientists are still exploring whether they are involved in the behaviour of the neurons in our brains. But I do believe that they are right that no-one has yet demonstrated how consciousness and free will could emerge from any logical, deterministic system; and I’m convinced by their arguments that they cannot emerge from such systems – in other words, from any system based on current computing technology. Steve Grand’s robot “Lucy” will never achieve consciousness.
Will more recent technologies such as biotechnology, nanotechnology and quantum computing ever recreate the equivalent of human experience and behaviour in a way that digital logic and classical physics can’t? Possibly. But any such development would be artificial life, not artificial intelligence. Artificial lifeforms – which in a very simple sense have already been created – could potentially experience the world similarly to us. If they ever become sufficiently sophisticated, then this experience could lead to the emergence of free-will, values and judgements.
But those values would not be our values: they would be based on a different experience of “life” and on empathy between artificial lifeforms, not with us. And there is therefore no guarantee at all that the judgements resulting from those values would be in our interest.
Why Stephen Hawkings, Bill Gates and Elon Musk are wrong about Artificial Intelligence today … but why we should be worried about Artificial Life tomorrow
Recently prominent technologists and scientists such as Stephen Hawking, Elon Musk (founder of PayPal and Tesla) and Bill Gates have spoken out about the danger of Artificial Intelligence, and the likelihood of machines taking over the world from humans. At the MIT Conference last week, Andy McAfee hypothesised that the current concern was caused by the fact that over the last couple of years Artificial Intelligence has finally started to deliver some of the promises it’s been making for the past 50 years.

(Self-replicating cells created from synthetic DNA by scientist Craig Venter)
But Andy balanced this by recounting his own experiences meeting some of the leaders of the most advanced current AI companies, such as Deepmind (a UK startup recently acquried by Google), or this article by Dr. Gary Marcus, Professor of Psychology and Neuroscience at New York University and CEO of Geometric Intelligence.
In reality, these companies are succeeding by avoiding some of the really hard challenges of reproducing human capabilities such as common sense, free will and value-based judgement. They are concentrating instead on making better sense of the physical environment, on processing information in human language, and on creating algorithms that “learn” through feeback loops and self-adjustment.
I think Andy and these experts are right: artificial intelligence has made great strides, but it is not artificial life, and it is a long, long way from creating life-like characteristics such as experience, values and judgements.
If we ever do create artificial life with those characteristics, then I think we will encounter the dangers that Hawkings, Musk and Gates have identified: artificial life will have its own values and act on its own judgement, and any regard for our interests will come second to its own.
That’s a path I don’t think we should go down, and I’m thankful that we’re such a long way from being able to pursue it in anger. I hope that we never do – though I’m also concerned that in Craig Venter and Steve Grand’s work, as well as in robots such as BINA48, we already are already taking the first steps.
But I think in the meantime, there’s tremendous opportunity for digital technology and traditional artificial intelligence to complement human qualities. These technologies are not artificial life and will not overthrow or replace humanity. Hawkings, Gates and Musk are wrong about that.
The human value of the Experience Economy
The final debate at the MIT conference returned to the topic that started the debate over dinner the night before with McAfee and Brynjolfsson: what happens to mass employment in a world where digital technology is automating not just physical work but work involving intelligence and decision-making; and how do we educate today’s children to be successful in a decade’s time in an economy that’s been transformed in ways that we can’t predict?
Andy said we should answer that question by understanding “where will the economic value of humans be?”
I think the answer to that question lies in the experiences that we value emotionally – the experiences digital technology can’t have and can’t understand or replicate; and in the profound differences between the way that humans think and that machines process information.
It’s nearly 20 years since a computer, IBM’s Deep Blue, first beat the human world champion at Chess, Grandmaster Gary Kasparov. But despite the astonishing subsequent progress in computer power, the world’s best chess player is no longer a computer: it is a team of computers and people playing together. And the world’s best team has neither the world’s best computer chess programme nor the world’s best human chess player amongst its members: instead, it has the best technique for breaking down and distributing the thinking involved in playing chess between its human and computer members, recognising that each has different strengths and qualities.
But we’re not all chess experts. How will the rest of us earn a living in the future?
I had the pleasure last year at TEDxBrum of meeting Nicholas Lovell, author of “The Curve“, a wonderful book exploring the effect that digital technology is having on products and services. Nicholas asks – and answers – a question that McAfee and Brynjolfsson also ask: what happens when digital technology makes the act of producing and distributing some products – such as music, art and films – effectively free?
Nicholas’ answer is that we stop valuing the product and start valuing our experience of the product. This is why some musical artists give away digital copies of their albums for free, whilst charging £30 for a leather-bound CD with photographs of stage performances – and whilst charging £10,000 to visit individual fans in their homes to give personal performances for those fans’ families and friends.
We have always valued the quality of such experiences – this is one reason why despite over a century of advances in film, television and streaming video technology, audiences still flock to theatres to experience the direct performance of plays by actors. We can see similar technology-enabled trends in sectors such as food and catering – Kitchen Surfing, for example, is a business that uses a social media platform to enable anyone to book a professional chef to cook a meal in their home.
The “Experience Economy” is a tremendously powerful idea. It combines something that technology cannot do on its own – create experiences based on human value – with many things that almost all people can do: cook, create art, rent a room, drive a car, make clothes or furniture. Especially when these activities are undertaken socially, they create employment, fulfillment and social capital. And most excitingly, technologies such as Cloud Computing, Open Source Software, social media, and online “Sharing Economy” marketplaces such as Etsy make it possible for anyone to begin earning a living from them with a minimum of expense.
I think that the idea of an “Experience Economy” that is driven by the value of inter-personal and social interactions between people, enabled by “Sharing Economy” business models and technology platforms that enable people with a potentially mutual interest to make contact with each other, is an exciting and very human vision of the future.
Even further: because we are physical beings, we tend to value these interactions more when they occur face-to-face, or when they happen in a place for which we share a mutual affiliation. That creates an incentive to use technology to identify opportunities to interact with people with whom we can meet by walking or cycling, rather than requiring long-distance journeys. And that incentive could be an important component of a long-term sustainable economy.
The future our children will choose

(Today’s 5 year-olds are the world’s first generation who grew up teaching themselves to use digital information from anywhere in the world before their parents taught them to read and write)
I’m convinced that the current generation of Artifical Intelligence based on digital technologies – even those that mimic some structures and behaviours of biological systems, such as Steve Grand’s robot Lucy, BINA48 and IBM’s “brain-inspired” True North chip – will not re-create anything we would recognise as conscious life and free will; or anything remotely capable of understanding human values or making judgements that can be relied on to be consistent with them.
But I am also an atheist and a scientist; and I do not believe there is any mystical explanation for our own consciousness and free will. Ultimately, I’m sure that a combination of science, philosophy and human insight will reveal their origin; and sooner or later we’ll develop a technology – that I do not expect to be purely digital in nature – capable of replicating them.
What might we choose to do with such capabilities?
These capabilities will almost certainly emerge alongside the ability to significantly change our physical minds and bodies – to improve brain performance, muscle performance, select the characteristics of our children and significantly alter our physical appearance. That’s why some people are excited by the science fiction-like possibility of harnessing these capabilities to create an “improved” post-human species – perhaps even transferring our personalities from our own bodies into new, technological machines. These are possibilities that I personally find to be at the very least distasteful; and at worst to be inhuman and frightening.
All of these things are partially possible today, and frankly the limit to which they can be explored is mostly a function of the cost and capability of the available techniques, rather than being set by any legislation or mediated by any ethical debate. To echo another theme of discussions at last week’s MIT conference, science and technology today are developing at a pace that far outstrips the ability of governments, businesses, institutions and most individual people to adapt to them.
I have reasonably clear personal views on these issues. I think our lives are best lived relatively naturally, and that they will be collectively better if we avoid using technology to create artificial “improvements” to our species.
But quite apart from the fact that there are any number of enormous practical, ethical and intellectual challenges to my relatively simple beliefs, the raw truth is that it won’t be my decision whether or how far we pursue these possibilities, nor that of anyone else of my generation (and for the record, I am in my mid-forties).
Much has been written about “digital natives” – those people born in the 1990s who are the first generation who grew up with the Internet and social media as part of their everyday world. The way that that generation socialises, works and thinks about value is already creating enormous changes in our world.
But they are nothing compared to the generation represented by today’s very young children who have grown up using touchscreens and streaming videos, technologies so intuitive and captivating that 2-year-olds now routinely teach themselves how to immerse themselves in them long before parents or school teachers teach them how to read and write.

(“Not available on the App Store“: a campaign to remind us of the joy of play in the real world)
When I was a teenager in the UK, grown-ups wore suits and had traditional haircuts; grown-up men had no earrings. A common parental challenge was to deal with the desire of teenage daughters to have their ears pierced. Those attitudes are terribly old-fashioned today, and our cultural norms have changed dramatically.
I may be completely wrong; but I fully expect our current attitudes to biological and technological manipulation or augmentation of our minds and bodies to thoroughly change over the next few decades; and I have no idea what they will ultimately become. What I do know is that it is likely that my six-year old son’s generation will have far more influence over their ultimate form than my generation will; and that he will grow up with a fundamentally different expectation of the world and his relationship with technology than I have.
I’ve spent my life being excited about technology and the possibilities it creates; ironically I now find myself at least as terrified as I am excited about the world technology will create for my son. I don’t think that my thinking is the result of a mistaken focus on technology over human values – like it or not, our species is differentiated from all others on this planet by our ability to use tools; by our technology. We will not stop developing it.
Our continuing challenge will be to keep a focus on our human values as we do so. I cannot tell my son what to do indefinitely; I can only try to help him to experience and treasure socialising and play in the real world; the experience of growing and preparing food together ; the joy of building things for other people with his own hands. And I hope that those experiences will create human values that will guide him and his generation on a healthy course through a future that I can only begin to imagine.